Discover how the building blocks of TensorFlow works at the lower level and learn how to make the most of Tensor objects.
Originally from KDnuggets https://ift.tt/3klG5J4

365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Originally from KDnuggets https://ift.tt/3klG5J4
Originally from KDnuggets https://ift.tt/3nalj0T
Originally from KDnuggets https://ift.tt/36rxKyq
Originally from KDnuggets https://ift.tt/35fmK7Y

Hi, hope you are healthy and well.
We wanted to thank you for being a long time subscriber and for helping make Chatbots Life one of the most popular blogs on Chatbots and Conversational AI online.
The event features speakers from Google, Salesforce, IBM Watson, GoDaddy, ADP, Rasa, etc. It’s the perfect opportunity to discover how enterprises are using Conversational AI and to network with top industry experts.
Also, we wanted to inspire you to create more great Conversational AI systems!
So we created a special promo just for you and are offering you a Discounted Pass to the Chatbot Conference for only $29! This is $170 off our current price and this offer is limited to the first 25 people who register.
You can now attend the Chatbot Conference on NOV 17th for only $29.
Hope to see you there!
Stefan
Cheers!
Exclusive VIP Promo for Conversational AI Conference was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally from KDnuggets https://ift.tt/3likhPD
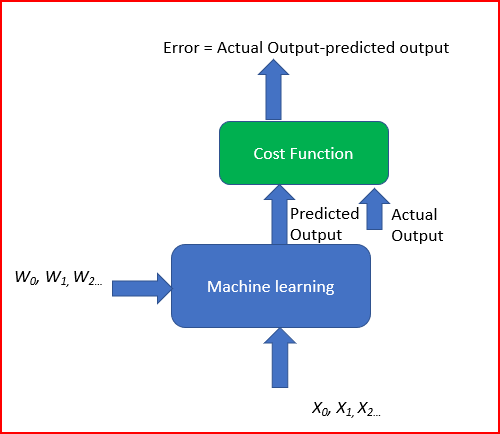
Over the course of this post, I will start to explain the purpose of algorithmic machine learning and the roles played by gradient decent…
Continue reading on Becoming Human: Artificial Intelligence Magazine »

If you landed on this page directly then wait you will have to read the first part of this series to get the idea of what’s going on here 🙂
Part 1 — Creating ML model for News Classification Link
Part 3— Creating News Classification Django App ( Part 2) Link
Part 4 — Deploying on Heroku and live on Web Link
In this part, I am going to create a News classification Django app on a local machine that can be deployed directly on Heroku. And wait if you are not familiar with Django but a python practitioner doesn’t worry I will try to explain in much detail as possible.
So first of all why I have chosen Django. Actually, in Python, there are 2 most common frameworks. Django and Flask and Django is a full-stack web framework, whereas Flask is a micro and lightweight web framework. And if you want to develop more complex Web Apps then absolutely Flask will not work out for you.
Moreover, Django is just an easy and very good framework for lazy peoples who don’t want to do too much code :). Many complex kinds of stuff are already present in a cooked form in Django, so without further delay let’s get started.

If you are using anaconda then first open the anaconda terminal and type
conda install -c anaconda django
or
pip install Django
The version of Django that I am using right now is Django 3.1.3. So, if in the future anybody is facing a problem then roll down to this version because you guys know about Python deprecated stuff :|.
Then move into your working directory in anaconda terminal any type.
django-admin startproject newsclassifier
This will create a project directory automatically and many of the settings and other stuff are already created in this directory which is the magic of Django.

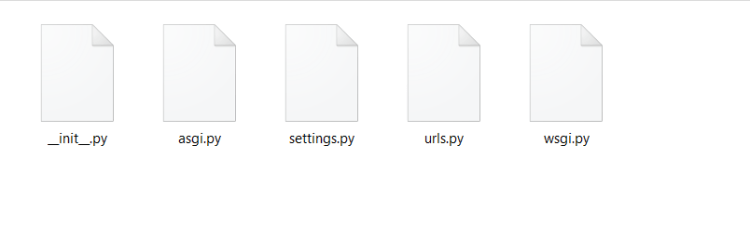
Open the “newsclassifier” directory and you will see a folder and a file name manage.py. Now open the “newsclassifier” folder inside that you will see 5 files that are present(in right of the picture). I will explain each file’s significance in detail in my way.
1. How to automatically deskew (straighten) a text image using OpenCV
3. 5 Best Artificial Intelligence Online Courses for Beginners in 2020
4. A Non Mathematical guide to the mathematics behind Machine Learning
But for now, a most interesting thing is that by just writing a 1 line in conda terminal you have already made a website. Yes, I know you will not believe it. So type the below command in your conda terminal.
cd newsclassifier
python manage.py runserver
After typing this you will see output like
Watching for file changes with StatReloader
Performing system checks...
System check identified no issues (0 silenced).
You have 18 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions.
Run 'python manage.py migrate' to apply them.
November 03, 2020 - 22:14:31
Django version 3.1.3, using settings 'newsclassifier.settings'
Starting development server at http://127.0.0.1:8000/
Quit the server with CTRL-BREAK.
You just have to copy HTTP URL and paste that into chrome / Mozilla or whatever and you will see this
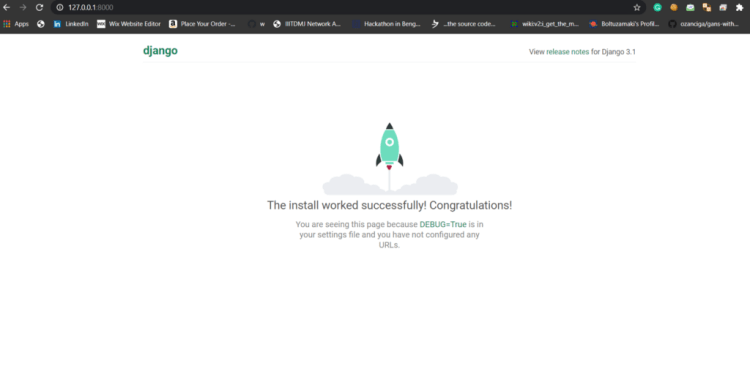
Now, do you believe one me? Yes actually your first website is live on your local machine but it doesn’t look like a news classifier isn’t it? Don’t worry just keep moving and you will get there soon.
By the way, manage.py is a command-line utility that lets you interact with the Django project in various ways.
Now first understand a basic thing that how our website will work. For news classification first, we have to make a python file, that can give an output of news category to our webpage. The webpage is the front end that we see on our web browser and it is made of HTML, CSS, and JS. So our workflow will be like when we type URL first, a page will appear on our browser which is decided by some function in backend and you will see a page which asks to type news and there is a button on which if we click, the typed news will be sent to the backend to that py file which we created. Which then load model and classify the text and send the news class in form of JSON back to our Webpage.
Confused? Wait let’s move step by step.
Creating views.py.
This file mainly handles the processing part of the data that comes from the front end and also helps to show the webpage on the browser according to the URLs that are called.
On a website, there is the main page that is the home page. This page is the first page that opens automatically when you type its domain name. like www.medium.com but if you click any link in the homepage then it will send you to the same website but in a different section, we can notice that the main name of the link is same but there is some other text added with it like www.medium.com/new-story here we can see that “new-story” is the additional text that is added when you open stories section in the medium. And also every new section contains different HTML pages and we need a link between our typed URL and the HTML pages.
So the link between our typed URL and the webpage which is going to open is done by two python files named urls.py and views.py. We register our URL in urls.py and also add a function which is going to be called if we type that URL. And the function is written in views.py.
Don’t worry if you find this confusing you will understand, what I have written in a few second.
First, create a file in “newsclassifier” directory name views.py and copy and paste this code.
from django.shortcuts import render
from django.http import HttpResponse
def home(request):
return HttpResponse('This is homepage')
actually, this means we are creating a function named home and when it called it will return a HttpResponse that can be read by browsers.
And now open the urls.py which is already created during starting the project. There may be some comments written on this py file you can remove it or leave it as it is.
from django.contrib import admin
from django.urls import path
from . import views # add this line
urlpatterns = [
path('admin/', admin.site.urls),
path('', views.home, name='index'), # add this line
]
‘admin/’ URL is already present there leave it as it is, you will get to know about admin panel in further tutorials for this one we do not need to worry about it. Just import your views.py and then in path function create a URL ‘ ’.This simply means when you type http://127.0.0.1:8000/ and add nothing in front of it then it will going to call a home function from views.py (views.home) and give it a name it may be anything you want I am giving it name ‘index’.
So if we run the server and type URL, it will go to URLs.py to search that if the typed URL is registered or not and if that URL is present in the file then it will further check that which function to call and from where. In our case function is home and it is called from views.py. and then home returns a text. Let see this works or not.
Again type the below code into your conda terminal if you have accidentally closed local server.
python manage.py runserver
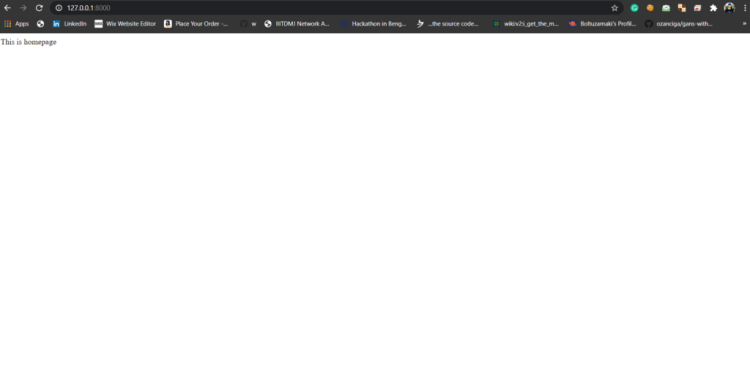
and then type http://127.0.0.1:8000/ in your web browser. Hurray, this is working :). Now we understand some basic thing time to make some more noise. We know that our homepage is not looking cool and for making any homepage cool we should have to make an Html page. But writing the whole code in HttpResponse is a very scary thing to do. So what we do is to write HTML code in a different file and save it in a folder named templates.
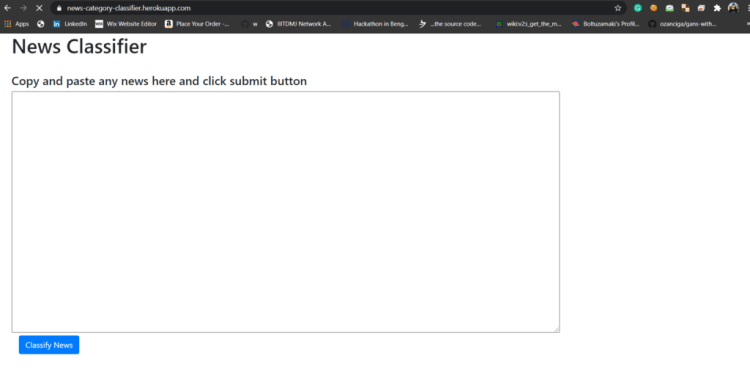
So we are going to make our homepage like this in which we have a huge text area where you can copy-paste your news and there is a button name classify news. Of course from using only HTML you can’t make pages beautiful. So what I have used here is Bootstrap. Those who not know about bootstrap in simple it is a framework which helps to make beautiful web pages by just copy and pasting code snippets that are provided on their official site and in very less effort.
I am not going to explain HTML code from scratch so you can just copy-paste it and if you want to change design then can use Bootstrap documentation. Now create an index.html file and copy-paste this stuffs.

your working directory should look like this. There should be a template folder and inside that index.html.
Now as we have created a folder from ourself that is not created at the start when we initialized our project. So this means that we have to tell somewhere that we have created a folder and add it into the project. For that go to newsclassfier directory and open settings.py. This file is the core file of our Django projects. It contains the configuration values which are needed by web apps to work properly such as database settings, static files location, template location, etc.
Now search for this code in that file
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
And the just add the name of folder ie. templates inside the ‘DIRS’: [], in above code and don’t forget the comma.
'DIRS': ["templates"],
Now by doing this, Django adds the template folder in the project setting. And now we can access stuff that we put in our template folder.
Now time for magic.
Just open your views.py and type.
from django.shortcuts import render
def home(request):
return render(request, 'index.html')
And save it and then run the server again if stopped.
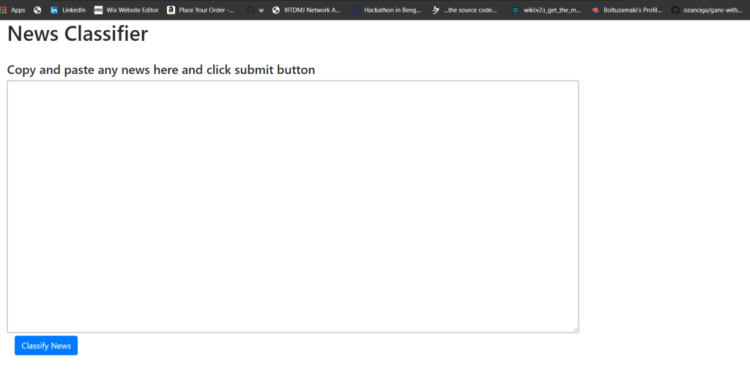
Woah! This is what looks like when you type the URL http://127.0.0.1:8000/ . Now our frontend is nearly ready but the button will not work because we haven’t tell it what to do when we click the button.
Also, this part is now already stretched long and I know you are excited but tired too. So take a break drink coffee and the Jump into the next part in which I will complete the whole website and make it run on locals.
And wait wait wait ! before moving on further if you like this article then you can give me a clap 🙂 and I am thinking to create many articles on real Web deployment projects in the field of ML, CV, and Reinforcement learning. So if you do not want to miss them. Follow me and stay tuned 🙂
Readers are most welcome to notify me if something is mistyped or written wrong.
My contacts.




Deploy your first ML model live on WEB (Part 2 ) was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.

If you don’t have a particular goal or project in mind, there is a wealth of open data available on the web to practice with. However, if you’re looking to tackle a specific problem, chances are you’ll need to collect data yourself or work with a company that can collect data for you.
There are many data collection companies that provide crowdsourcing services to help individuals and corporations gather data at scale. Working with a crowdsourcing partner allows teams to collect lots of diverse data at a fraction of the cost of traditional data collection methods.
Before you select a data collection partner, consider the following factors:
Without further ado, here are the top providers of data collection services.
Lionbridge AI is a data collection company that that partners with anyone with machine learning data needs, from research teams to the Fortune 500. While most other data collection companies do not support languages other than English, Lionbridge provides data services in over 300 languages. With solution centers in 27 countries, Lionbridge AI covers both simple data collection use cases as well as linguistically complex long-term projects. Unlike MTurk, Lionbridge manages the entire process, from designing workflows to sourcing qualified workers.
1. How to automatically deskew (straighten) a text image using OpenCV
3. 5 Best Artificial Intelligence Online Courses for Beginners in 2020
4. A Non Mathematical guide to the mathematics behind Machine Learning
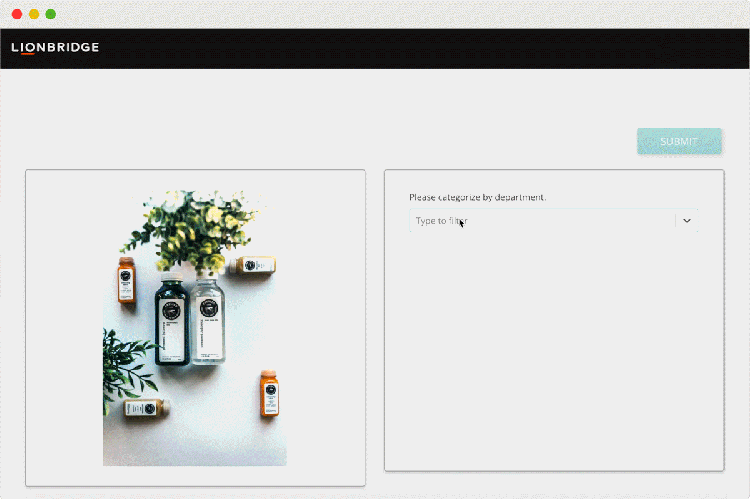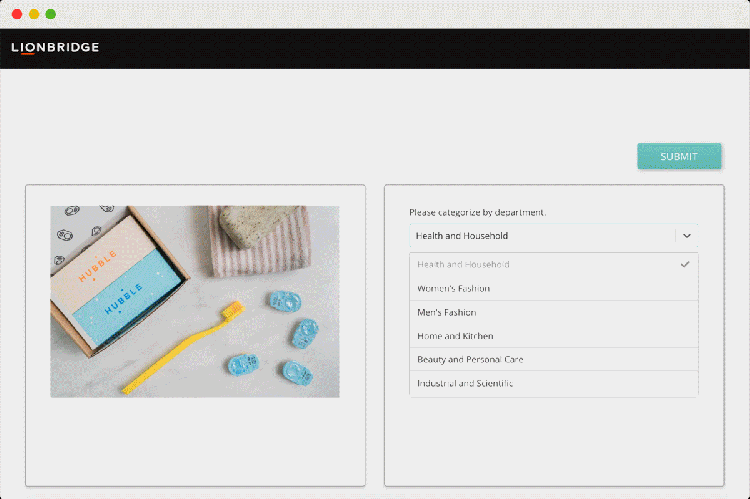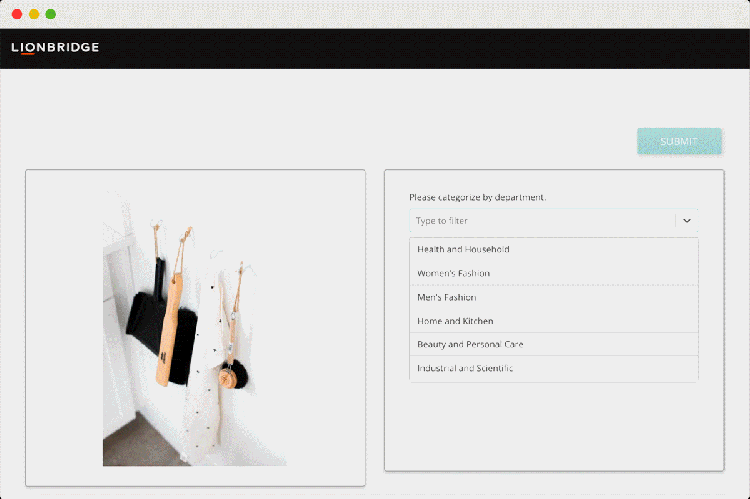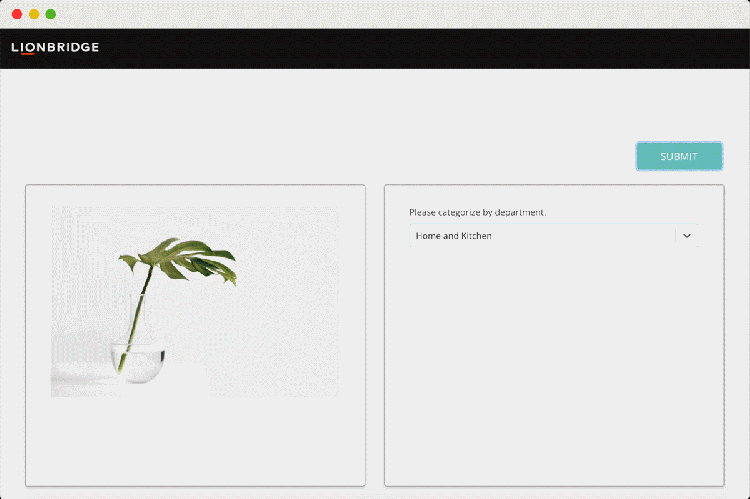
Working with Lionbridge unlocks access to a network of 500,000+ qualified linguists, in-country speakers, and experienced project managers capable of collecting data for a range of use cases. With over 20 years of experience, Lionbridge has built all the necessary crowd management capabilities necessary to source and manage thousands of contributors.
In addition to providing managed crowd services, Lionbridge AI also provides an open platform for users to design and manage their own data collection projects.
Also known as MTurk, Amazon Mechanical Turk is a crowdsourcing marketplace designed to recruit remote workers to complete labor-intensive tasks. These human intelligence tasks (HITs) range in length, complexity and compensation. MTurk has rapidly become a popular way to collect data for machine learning research due to its brand name and low cost appeal.
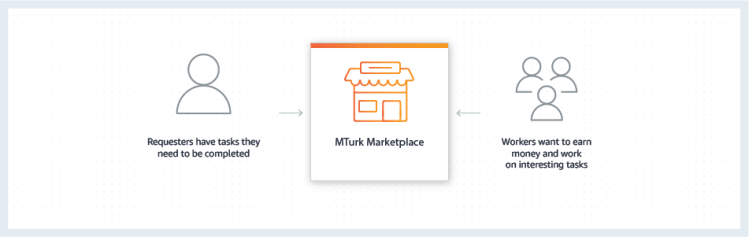
Despite these advantages, the tool is only feasible for small-scale data collection projects with budget constraints. While MTurk is often considered a cheap solution to data collection, there are actually many hidden costs. Requesters must be very explicit in defining HIT descriptions, which can be incredibly time consuming. As a result, good projects require a lot of effort to create and manage.
Another key problem in using MTurk to collect training data is the issue of quality control. The platform itself offers very little in the way of quality control mechanisms, advanced worker targeting, or detailed reporting. Whereas other companies conduct rigorous testing for their contributors, anybody with a computer and an internet connection can sign up and pick up jobs on MTurk.
Clickworker is a company based in Germany that offers a wide range of data collection and annotation services. The Clickworker crowd is comprised of registered users that perform small tasks (called microjobs) on their online platform. The company is capable of creating audio, photo and video datasets using its proprietary platform. Clickworker also supports a mobile application to make it easier to collect data from their contributors.
Appen is an Australian company that collects, annotates, and evaluates a variety of machine learning data types including speech, text, image, and video. The company uses remote crowdsourcing to complete tasks for AI use cases such as social media and online search evaluation. While much of Appen’s work revolves around moderating content, they also support data collection across a large number of languages. Being a service provider, Appen does not offer collection or annotation tools. Instead, they directly provide the data that they source through their crowd.
Globalme is a Vancouver-based data collection company. While the company doesn’t offer open access to the platform, they do offer crowd management and worker sourcing. In the past, Globalme has collected voice samples for smartwatches, speaker systems, in-car speech systems and general voice assistants. Aside from data collection, Globalme also offers testing and localization services.
On the hunt for the right data collection company? If you’re developing your own machine learning model, Lionbridge has over 20 years of experience and 1M+ staff ready to help. Whether you’re looking to train a virtual assistant or OCR system, Lionbridge is your home for crowdsourced data services.
Top 5 Data Collection Companies for Machine Learning Projects was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally from KDnuggets https://ift.tt/2GLiKCL
