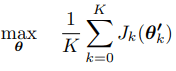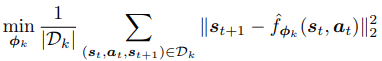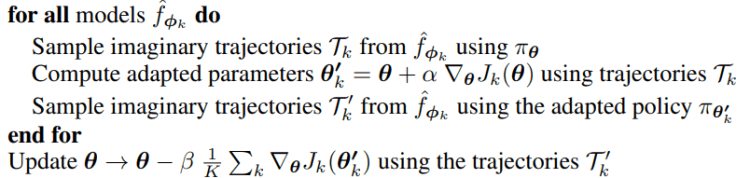365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
The results of any AI developed today is entirely dependent on the data on which it trains. If the data is distributed–intentionally or not–with a bias toward any category of data over another, then the AI will display that bias. What is a better way forward to handle this possibility toward bias when the datasets involve human beings?
A marketing analyst is one of the key figures within any company.
Marketing analysts not only help businesses utilize market data as a strategic tool to develop new products but they also interpret consumer behavior, refine business ideas, and even assess the viability of entering a new competitive sector. Naturally, the position has amazing potential in terms of career development, as it is high in demand across all industries, including consumer services, tech, and energy.
So, in this article, we’ll provide you with the most important information you need to become a marketing analyst.
You’ll learn who the marketing analyst is, what they do, how much they make, and what skills and degree you need to become one.
You can also check out our video on the topic below or scroll down to keep on reading.
What Is a Marketing Analyst and Why Are They So Important for Business Success?
Marketing is the fuel that provides power to the motor of a company – sales. Without substantial marketing efforts, organizations will have a hard time selling their products.
There are various roles within marketing and each one fulfills a particular function to keep the business going at full speed. And marketing analysts tend to be some of the most hands-on professionals in a company. Their role is truly versatile, encompassing a wide range of activities:
digital marketing
traditional/offline marketing
brand marketing
market research
marketing communications
retail marketing
B2B marketing, and so on..
The possibilities are endless.
However, we need to remember that a marketer’s primary goal, regardless of the channel – be it digital, traditional, or business-to-business, is to introduce a company’s products and showcase their value to customers. And in today’s data-rich environment, the success of a marketer is measured by their ability to leverage multiple sources of data to make informed decisions based on quantitative evidence.
A marketing analyst works closely with product owners and can be assigned to a particular product or, alternatively, to a specific channel. For example, a digital marketing analyst is usually responsible for a company’s social media accounts. They also handle the communication with agencies to discuss ad spend, upcoming campaigns, and the amount of promotional budget that can be allocated. A marketing analyst also collaborates frequently with the sales team and provides them with valuable insight when it comes to forecasting and resources that can be spent at a given time.
That’s the compact presentation of this exciting job role. But to get a better idea of what it means to be a marketing analyst, we need to take a closer look at their typical responsibilities.
What Does a Marketing Analyst Do?
A marketing analyst’s list of day-to-day tasks is super versatile and seemingly infinite. Some typical marketing analyst tasks involve providing feedback on copy and images prepared by agencies or in-house talent and making sure that brand guidelines have been followed. They are the ones responsible for running campaigns, as well as interacting with agencies reps and communicating results to marketing managers. Quite often, a marketing analyst in a company oversees a single product or channel. This not only gives them a true perspective on how the product or channel works but also reveals the dynamics that allow for more sales and improved brand awareness among the target audience.
If this sounds like something you’d like to do, you’ll probably get even more excited about the job, once you discover that it can be rewarding in terms of income, as well.
What Is the Marketing Analyst Salary?
How much does a marketing analyst make? According to Glassdoor, a marketing analyst makes $54,155 on average. So, if you’re just starting your marketing analyst career, expect a median entry level marketing analyst salary of $39k a year. Of course, a senior marketing analyst salary can go up to $76k!
What Is the Marketing Analyst Career Path?
The marketing analyst job is a great option to explore on its own but also as an entry-level position that could open the door to a marketing manager position. And, if you’re determined enough, you can rise through the ranks and become a Chief Marketing Officer!
Usually, in a smaller firm, marketing analysts have more responsibilities. This allows them to gain a holistic view of all activities. In a larger organization, where marketing budgets are generally larger, they tend to specialize in a particular aspect and work on it extensively. Either way, there are plenty of opportunities across all fields, including the consumer, FMCG, and telecom industries.
What are the Key Skills You Need to Apply for Marketing Analyst Jobs?
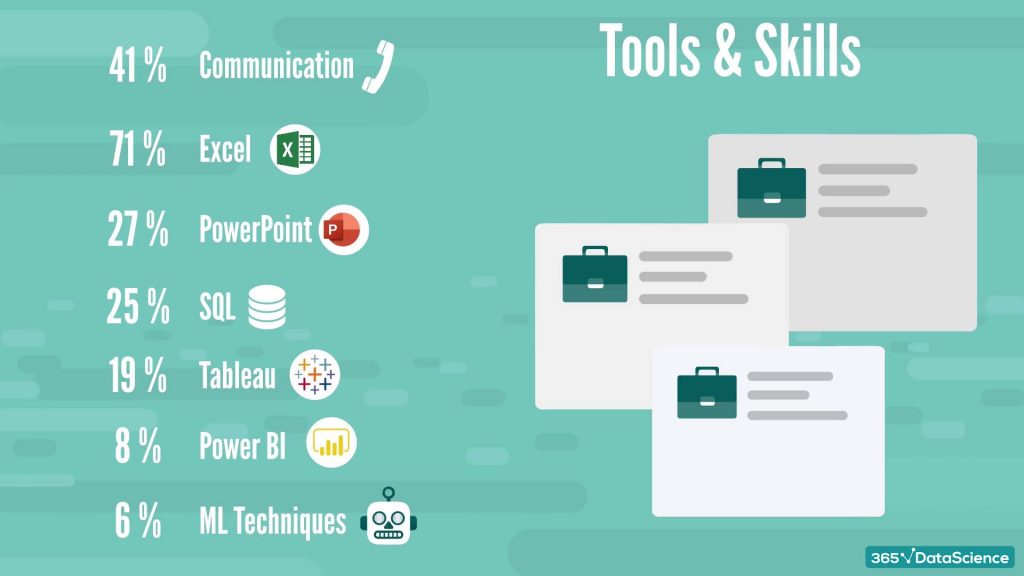
We researched many job ads to discover the most in-demand tools and skills marketing analyst candidates must have.
Among the other notable mentions in the marketing analyst skills category are technologies like:
ERP
SPSS
Google Analytics
Qlik Sense
Stata
SAS
Let’s elaborate on this.
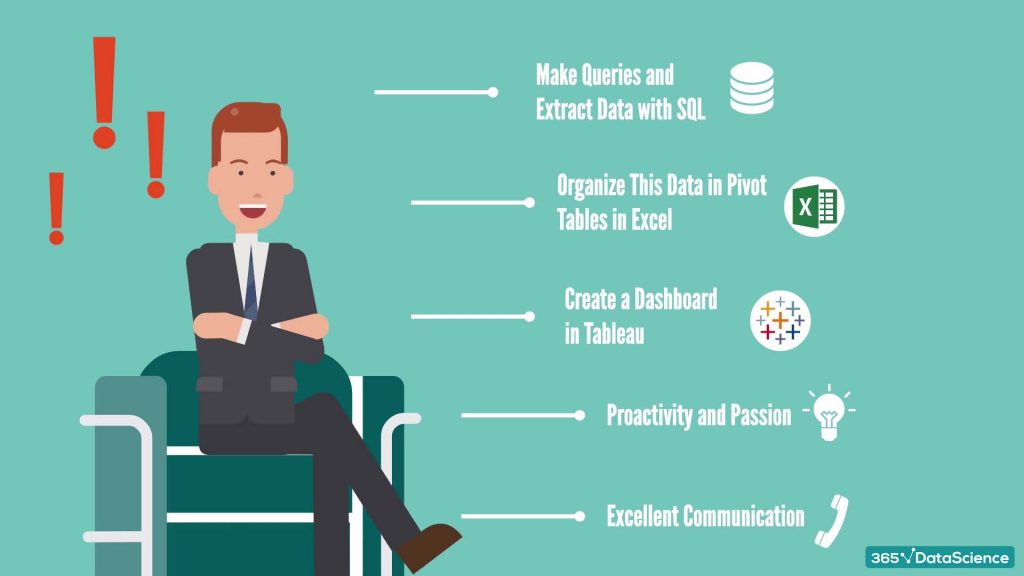
The numbers in every marketing analyst job description are very clear on one thing. Every marketing practitioner needs analytics. It’s what helps them make sense of the different figures coming from various channels, client types, and product configurations.
They have to understand Hypothesis testing and A/B testing. Especially if they work online, which nowadays is a must for almost everyone.
What’s more, today, marketing professionals also need to leverage Tableau and Power BI. Such dashboard software helps them self-serve their analysis needs and make adjustments in real-time.
But analyzing quantitative input is far from the only requirement of the job. Marketing analysts should exude both proactivity and passion for the brand. Besides, as the research clearly points out, they must be excellent communicators, as well.
What Is the Required Marketing Analyst Degree?
In terms of academic degree, a Bachelor’s degree was quoted in 66% of the job offers, while a Master’s – in a mere 6%. And the good news for those of you who hold undergraduate degrees and lack professional experience doesn’t stop here.
What Is the Necessary Marketing Analyst Experience?
When it comes to years on the job, the average expectation of employers is 3.6 years. However, a whole 39% of jobs didn’t require any experience at all! So, that certainly gives you a good chance to land a marketing analyst job straight after college graduation.
Now you know the most important aspects of the marketing analyst position, what to expect from the job, and what skills to acquire to become one.
However, if you are looking to start a marketing analyst career but you feel that you need to level up your skillset, check out our Customer Analytics in Python course. It will guide you all the way from the marketing fundamentals, through customer and purchase analytics, to building a deep-learning model to predict customer behavior, all implemented in Python.
Combining PyTorch and Google’s cloud-based Colab notebook environment can be a good solution for building neural networks with free access to GPUs. This article demonstrates how to do just that.
Cloud migration requires a careful planning process to ensure all systems work as they should. Use this checklist, sponsored by Immuta and TDWI, to learn seven best practices for data teams migrating sensitive data to the cloud.
Reinforcement Learning (RL) provides a mathematical formalism for learning-based control. In Deep Reinforcement Learning (DRL), a neural network with reinforcement learning is used to enhance the algorithm the ability to control the system with extremely high-dimensional input spaces such as images [1]. Learning from limited samples is one of the challenges which can be faced when DRL is applied to a real-world System. Almost all real-world systems are either slow, fragile, or expensive enough that the data they produce is costly, and policy learning must be data-efficient [2]. Model-based reinforcement learning approaches make it possible to solve complex tasks given just a few training samples.
In model-based RL, the data is used to build a model of the environment. Since the model is trained on every transition, model-based RL algorithms effectively receive more supervision, and the other benefit of those methods that they are trained with supervised learning, which is more stable opposing to bootstrapping. There are many recipes for model-based reinforcement learning [3]. The one described in the article uses the learned model as a simulator to generate “synthetic” data to augment the data set available to improve the policy. One of the problems that can arise is that policy optimization tends to exploit regions where the model is inaccurate (e.g., due to a lack of data). This issue is called model bias. Standard countermeasures from the supervised learning literature, such as regularization or cross-validation, are not sufficient to solve this issue [7]. There are two distinct classes of uncertainty: aleatoric (inherent system stochasticity) and epistemic (due to limited data). One way to deal with the exploitation of model inaccuracies is to incorporate uncertainty into the predictions of our model.
There are many possibilities to capture model uncertainty for model-based RL. Gaussian processes [5] and Bayesian neuronal networks incorporate uncertainty directly but are not suitable for complex tasks. Other Methods can be used to approximate model uncertainty like model ensembles [7] and dropout [6].
The assessment of uncertainty is not only of crucial importance in model-based RL but also in modern decision-making systems. Kahn used uncertainty estimation for obstacle avoidance and reward planning. Berkenkamp used the uncertainty estimation to make exploration safer.
Machine Learning Jobs
Model-Ensemble
The focus of this article will be on the ensembles method. Or more precisely: How we can use an ensemble of networks to represent the uncertainty and apply it to reinforcement learning algorithms. Beginning with some results from our experiment, where we trained an ensemble of 3 models to approximate the motion of a robot arm moving to push an object. The following diagram shows the result for the 70-steps prediction
Kurutach et al. [7] propose to regularize the policy updates using an ensemble of models that can be used to model the uncertainty, to tackle the model bias problem.
In the models’ update step, a set of K dynamics models is trained with supervised learning using the data collected from the real-world. The models’ weights are initialized independently and trained on mini-batches in different orders. In the policy update step, Trust Region Policy Optimization (TRPO) [9] is used to optimize the policy using virtual stochastic rollouts. Each virtual step is uniformly sampled from the ensemble predictions, which leads to more stable learning because the policy does not overfit to any single model. The last step is the policy validation step, where the policy is validated after every n gradient updates using the K learned models. If the ratio of models in which the policy improves exceeds a specified threshold, the current iteration continues. If not, then the current iteration is terminated, and the actual policy will be used to collect more real-world data to improve the model ensemble.
The learned policy will be robust against various scenarios it may encounter in the real world. To Evaluate the algorithm first, they compared ME-TRPO with the Vanilla Model-Based RL algorithm, to show the effect of using model-free algorithms to update the policy. They found that ME-TRPO leads to much better performance. Second, they compare it with state-of-the-art Model-Free methods in terms of sample complexity and final performance. Finally, they evaluated the used ensemble. They found that more models in the ensemble lead to improve the policy because the learning is better regularized. On the other hand, the resulted policy is more conservative because it has to get a good performance on all the models.
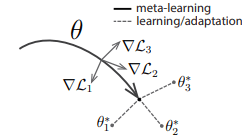
Model-Based Meta Policy-Optimization [8] shares the same trajectory sampling scheme as ME-TRPO but utilizes the model-generated data differently. In MB-MPO, meta-learning aims to learn a policy that adapts fast to new tasks. Each task corresponds to a different belief of what the real environment dynamics might be. In other words, it is the dynamics of different learned models, but they share the same action-space, state-space, and reward function.
Diagram of the model-agnostic meta-learning algorithm (MAML), which optimizes for a representation θ that can quickly adapt to new tasks [10]
In an adaptation step, Vanilla Policy Gradient (VPG) is used to form a task-specific policy from a meta-policy
A policy gradient step adapts meta-policy to policy for task k
with Jk(θ) being the expected return under the policy πθ. Trust Region Policy Optimization (TRPO) is used for maximizing the meta-objective
the meta-objective
where K is the number of tasks or the number of models in the ensemble. The meta-objective aims to find a good meta-policy that can be adjusted with a gradient step to use it for K tasks and get maximum reward for each of these tasks.
Models’ update step Trajectories are sampled from the real environment with the adapted tasks’ policies θ1,…, θK, and added to a data set D. These trajectories are used to train all models. The objective of learning each model is to minimize the L2 one-step prediction loss:
update model objective function
Task policies and meta-policy update step The following pseudo-code shows that the update of the policy step uses only imaginary trajectories generated from all the models in the ensemble
Update meta-policy and tasks-policies [8]
There are many advantages to this algorithm:
Regularization effect during training this effect prevents the policy from learning sub-optimal behaviors that arise in robust policy optimization (ME-TRPO).
Tailored data collection for fast model improvement Using K policies to collect real-world data generates diverse data. This effect accelerates correcting the imprecision of the Ensemble models leading to more rapid improvement.
Fine-tuning the policy with VPG on the real environment leads to faster convergence than training the policy from scratch.
Simplicity.
Model-Based Value Expansion (MVE)
The goal of Model-Based Value Expansion [11] is to improve both sample efficiency and performance by utilizing a learned dynamics model to enhance state-action value estimates, namely, to improve the targets for temporal difference learning.
For this, the authors expand the state-action value at an arbitrary state Q(s0) into an H-step trajectory generated by the model and tail estimated by Q(sH). Assuming the dynamics model to be accurate up to the horizon, this yields higher accuracy in state-action values than the original estimate Q(s0).
On the other side, because of the fixed-length “rollouts” an into the future, potentially accumulating model errors or increasing value estimation error along the way. dynamics model to compute “rollouts” that are used to improve the targets for temporal difference learning.
Model-Based Policy Optimization (MBPO)
In MBPO [12], a dynamic transition distribution Tθ(st+1|st, at) parametrized by θ is learned via supervised learning on the sampled data from the data collection policy. During training, MBPO performs k-step rollouts using Tθ starting from state s ∈ Denv. MBPO iteratively collects samples from the environment and uses them to improve both the model and the policy further. Policy optimization algorithms may exploit these regions where the model is inaccurate.
Open Points
How to use the model ensemble to encourage the policy to explore the state space where the different models disagree?
This article was written with the help of Jan Bieser and Moritz Zanger.
References
[1] V. Mnih, K. Kavukcuoglu, D. Silver, Al. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller, “Playing atari with deep reinforcement learning.” [2] G. Dulac-Arnold, Daniel J. Mankowitz, and Todd Hester, “Challenges of real-world reinforcement learning.” [3] T. Wang, X. Bao, I. Clavera, J. Hoang, Y. Wen E. Langlois, “Benchmarking Model-Based Reinforcement Learning” [4] R. S. Sutton and A. Barto “ Reinforcement Learning: An Introduction” [5] M. Deisenroth and C. Rasmussen, “PILCO: A Model-Based and DataEfficient Approach to Policy Search.” [6] Y. Gal, and Z. Ghahramani, “Dropout as a Bayesian approximation: Representing model uncertainty in deep learning.” [7] T. Kurutach, I. Clavera, Y. Duan, A. Tamar, and P. Abbeel, “Model-Ensemble Trust-Region Policy Optimization” [8] I. Clavera, J. Rothfuss, J. Schulman, Y. Fujita, T. Asfour, and P. Abbeel, “Model-Based Reinforcement Learning via Meta-Policy Optimization,” [9] J. Schulman, S.Levine, P. Abbeel, M. Jordan, P. Moritz, “Trust Region Policy Optimization” [10] C. Finn, P. Abbeel, S. Levine, “Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks” [11] V. Feinberg, A. Wan, I. Stoica, M. I. Jordan, J. E. Gonzalez, S. Levine, “Model-Based Value Estimation for Efficient Model-Free Reinforcement Learning” [12] M. Janner, J. Fu, M. Zhang, and S. Levine, “When to trust your model: Model-based policy optimization.”
Understanding how to build AI models is one thing. Understanding why AI models provide the results they provide is another. Even more so, explaining any type of understanding of AI models to humans is yet another challenging layer that must be addressed if we are to develop a complete approach to Explainable AI.