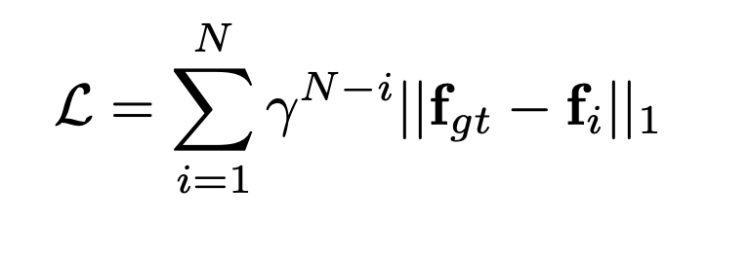365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Also: 13 must-read papers from AI experts; 10 Pandas Tricks to Make My Data Analyzing Process More Efficient: Part 2 – Tricks I wish I had known earlier; An Introduction To Mathematics Behind #NeuralNetworks; How to Write Web Apps Using Simple #Python for #DataScientists
How’s it going, 365 family? My name is Andrew from DataLeap and I’m happy to team up with 365 Data Science in their series 365 Data Use Cases. So, what’s my favorite data use case? Recommender systems!
Recommender Systems Use Cases: Google, YouTube, Facebook, Instagram, and Amazon
When you think of FAANG companies, what pops into your mind? Netflix and their newest dating show suggestion, Google and YouTube’s home page, Facebook, and Instagram’s feed. For B2C companies like Amazon, selling you a recommended product directly lifts their bottom line: sales revenue. But for companies that rely on content, connections, and curation, things are a bit different. Giving you a recommended video or mobile game keeps you on their platform longer. This is beneficial in a subtler way, usually increasing CTR (click-through rate) which leads to higher watch time or session time to lift ads revenue and in-app purchases.
You can check out everything I have to say on the topic in the video below or just scroll down to keep on reading.
YouTube Recommendation Algorithm
Before we get too technical, think about what data Google can even use for a YouTube recommender model: the infamous YouTube Recommendation Algorithm. Google has a sense of what videos you like based on your behavior on (or off) YouTube. Besides, they have a sense of what type of users you are similar to based on your demographic and information you’ve willingly shared with Google. If your friend Clair went to the same high school as you, has a similar search history for French cooking tutorials, and shared a video about eclairs on YouTube, then you will likely see that same video on your home page since Google recommendation engine is aware you compare to Claire and their eclectic eclair shares. So take care where you share your personal preferences.
Google Recommendation Engine
Let’s understand recommender systems from the source, the King Regent of Recommendations: Google. Google provides free courses on how to pass their developer interviews. In the section about recommendation systems, Google considers the value add of a model that helps users find compelling new content among millions of Google store apps and billions of YouTube videos.
Recommendation System Architecture
Now let’s get technical. One common recommendation system architecture looks like this:
1. Candidate generation
In the candidate generation stage, the recommendation system considers a large group of videos. This is called a corpus. Reducing billions into hundreds is the goal, and evaluating whether a video is a good candidate quickly is the key. Rigor and speed are competing against each other, especially since a recommender system might incorporate many nominators that vote on videos for better results but slower performance.
2. Scoring
The next stage involves a more precise model parsing through fewer than 100 candidates, ranking them so that the user sees the best first. The scoring section, of course, takes in your personal data as I mentioned earlier, but it also thinks about the following:
“Local” vs “distant” items; that is, taking geographic information into account
Popular or trending items
A social graph; that is, items liked or recommended by friends
Now hold on, you might ask. Why not let the candidate generator score as well. There’s a couple of reasons:
Some systems rely on multiple candidate generators. The scores of these different generators might not be comparable.
With a smaller pool of candidates, the system can afford to use more features and a more complex model that may better capture context.
This goes hand in hand with the final stage: re-ranking.
3. Re-ranking
Re-ranking takes into consideration content that the user has already disliked, how new the content is, and other factors. This is how YouTube promotes diversity, freshness, and fairness.
Now you have a good initial idea of what recommender systems are and how the biggest and the best companies use them to reach their business goals.
However, if you enjoy comedy and compelling data storytelling with corgis, head over to my YouTube channel DataLeap and my second channel The DataLeap Andrew Show.
And, if you want to dive deeper into the subject of recommender systems and machine learning, check out the 365 Data Science course in Machine Learning in Python for beginners.
I’m a recently graduated engineer with a degree in artificial intelligence. As a computer scientist, I am motivated largely by my curiosity of the world around us and seeking solutions to its problems. I am also counting on you to send me comments that will help me improve the quality of the articles and improve myself.
The optical flow is the apparent movement of objects in a scene, concretely we want to know if a car is moving, in which direction or how fast it is moving.
Optical flux provides a concise description of both the regions of the moving image and the speed of movement. In practice, optical flow computation is sensitive to variations in noise and illumination. It is often used as a good approximation of the actual physical motion projected onto the image plane.
Figure 2: motion colors
To represent the movement of an object in an image we use movement colors, the color indicates the direction of movement of the object, the intensity the speed of movement.
Artificial Intelligence Jobs
The traditional approach to deal with an optical flow problem
Optical flow has traditionally been approached as a hand-crafted optimiza- tion problem over the space of dense displacement fields between a pair of images. The concept is to try to determine the velocity of the brightness pattern.
You are going to tell me, how to define the speed of movement of an object in an image with an optimization problem?
The principle is very simple, we define the energy of a pixel or the intensity of a pixel by the following function E(x, y, t) where x and y represents the position of the pixel. The position of the pixel is estimated after a minor change in time to do that it uses derivative. We consider the hypothesis that during a small time variation the intensity of the pixel has not been modified (1).
figure 3: demo
||uv|| is simply the speed of movement of the pixel within the plane. Traditionally, optical flow problems have been limited to estimating the speed of movement of a pattern within an image. I have introduced the basics of the problem, however we can’t define ||uv||| directly. We have to add other constraints. For those who are interested I leave you the link that explains the method in its entirety link.
RAFT (Recurrent All-Pairs Field Transforms)
RAFT is a new method based on deep learning methods presented at ECCV (European Conference for Computer Vision) 2020 for optical flows. This new method, introduced by Princeton researchers, reduces F1-all error by 16% and becomes the new state of the art for optical flows. RAFT has strong cross-dataset generalization as well as high efficiency in inference time, training speed, and parameter count.
In this article I will present the different bricks that make up RAFT:
Feature encoder
multi-scale 4D correlation volumes
update operator
figure 4: RAFT
Feature Encoder
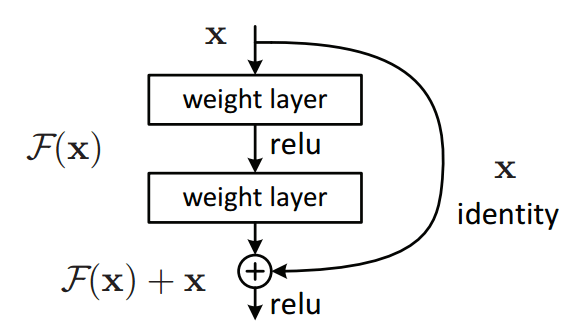
The role of the feature encoder is to extract a vector for each pixel of an image. The feature encoder consists of 6 residual blocks, 2 at 1/2 resolution, 2 at 1/4 resolution, and 2 at 1/8 resolution.
figure 5: Residual block
The common culture believes that increasing the depth of a convoluted network increases its accuracy. However, this is a misconception, as increasing the depth can lead to saturation due to problems such as the vanishing gradient. To avoid this, we can add residual blocks that will reintroduce the initial information at the output of the convolution layer and add it up.
We additionally use a context network. The context network extracts features only from the first input image 1(Frame 1 on the figure 4). The architecture of the context network, hθ is identical to the feature extraction network. Together, the feature network gθ and the context network hθ form the first stage of this approach, which only need to be performed once.
Multi-Scale 4D correlation volumes
To build the correlation volume, simply apply the dot product between all the output features of the feature encoder, the dot product represents the alignent between all feature vectors. The output is the dimensional correlation volume C(gθ(I1),gθ(I2))∈R^H×W×H×W.
Correlation Pyramid
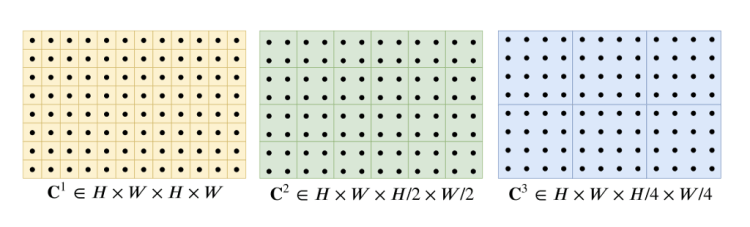
figure 6: Correlation pyramid
They construct a 4-layer pyramid {C1,C2,C3,C4} by pooling average the last two dimensions of the correlation volume with kernel sizes 1, 2, 4, and 8 and equivalent stride (Figure 6). Only the last two dimensions are selected to maintain high-resolution information that will allow us to better identify the rapid movements of small objects.
C1 shows the pixel-wise correlation, C2 shows the 2×2-pixel-wise correlation, C3 shows the 4×4-pixel-wise.
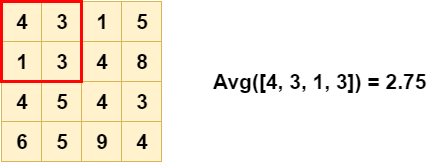
Figure 7: Average Pooling part 1
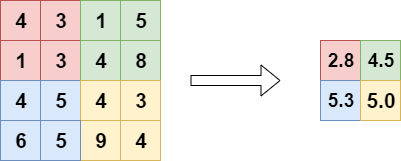
An exemple of average pooling with kernel size = 2, stride = 2. As you can see on figure 7 and 8, Average Pooling compute the average selected by the kernel.
figure 8: Average Pooling final result
Thus, volume Ck has dimensions H × W × H/2^k× W/2^k . The set of volumes gives information about both large and small displacements.
Correlation Lookup
They define a lookup operator LC which generates a feature map by indexing from the correlation pyramid.
How does indexing work?
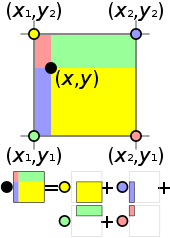
Each layer of the pyramid has one dimension C_k = H × W × H/(2^k)× W/(2^k). To index it, we use a bilinear interpolation which consists in projecting the matrix C_k in a space of dimension H × W × H × W.
Figure 9: bilinear interpolation
To define a point à coordinate (x, y), we used four points (x1, y2), (x1, y1), (x2, y2) and (x2, y1). Then compute new point (x, y2), (x1, y), (x, y1) and (x2, y) by interpolation, then repeat this step to define (x, y).
Given a current estimate of optical flow (f1,f2), we map each pixel x = (u,v) in image 1 to its estimated correspondence in image 2: x′ = (u + f1(u), v + f2(v)).
Iterative Updates
For each pixel of image 1 the optical flux is initialized to 0, from image 1 we will look for the function f which allows to determine the position of the pixel within image 2 from the multi scale correlation. To estimate the function f, we will simply look for the place of the pixel in image 2.
We will try to evaluate function f sequentially {f1, …, fn}, as we could do with an optimization problem. The update operator takes flow, correlation, and a latent hidden state as input, and outputs the update ∆f and an updated hidden state.
By default the flow f is set to 0, we use the features created by the 4D correlation, and the image to predict the flow. The correlation allows to index to estimate the displacement of a pixel. We then use the indexing between the correlation matrix and image 1 in output of the encoder context to estimate a pixel displacement between image 1 and 2. To do this, a GRU (Gated Recurrent Unit) recurrent network is used. As input the GRU will have the concatenation of the 4D correlation matrix, the flow and image 1 as output of the context encoder. A normal GRU works with fully connected neural networks, but in this case, in order to adapt it to a computer vision problem, it has been replaced by convoluted neural networks.
figure 10: GRU with convolution
To simplify a GRU works with two main parts : the reset gate that allows to remove non-essential information from ht-1 and the update gate that will define ht. The gate remainder is mainly used to reduce the influence of ht-1 in the prediction of ht. In the case where Rt is close to 1 we find the classical behavior of a recurrent neural network. . This determines the extent to which the new state ht is just the old state ht-1 and by how much the new candidate state ~ht is used.
figure 11: GRU with with fully connected layers
In our case we use the GRU, to update the optical flow. We use the correlation matrix and image 1 as input and we try to determine the optical flux, i.e. the displacement of a pixel u(x, y) in image 2. We use 10 iteration, i.e. we calculate f10 to estimate the displacement of this pixel.
Loss
figure 12: Loss function
The loss function is defined as the L1 standard between the ground truth flow and the calculated optical flow. We add a Gamma weight that increases exponentially, meaning that the longer the iteration in the GRU the more the error will be penalized. For example let’s take the case where fgt = 2, f0 = 1.5 and f10= 1.8. If we calculate the error L0 = 0.8¹⁰*0.5 = 0.053, L10 = 0.8⁰*0.2=0.2. We quickly understand that an error will be more important at the final iteration than at the beginning.
figure 13: example of optical flow prediction with RAFT
With a simple Google search for the words’ artificial intelligence’ producing a staggering 734,000,000 results- the notion of AI has slowly made its way into the mainstream. It is now considered to be a staple in the cybersecurity diets of many. Despite the countless articles written on AI applications within several businesses and industries, most individuals are still in the dark about artificial intelligence’s dual nature.
Considering the ever-evolving threat landscape of today, staying unaware of the potential threat posed by artificial intelligence can prove to be lethal for most organizations operating in today’s digital climate. Simply put, the sooner companies come to terms with the fact that AI is a double-edged sword, the better.
Artificial Intelligence Jobs
To aid our readers in understanding the two sides of AI, we’ve compiled an article that depicts both sides of the AI coin. Since artificial intelligence relies heavily on developing systems and programs capable of emulating human behavior, hackers can manipulate these AI technologies to give rise to ‘intelligent’ stealth attacks and malware programs. Typically, these malware programs are equipped to adapt to changes in their environments, making them all the more dangerous. To know more about it, bear with us.
The Positive Side of AI
When the concept of AI was first introduced, most individuals tended to overlook the security potential of artificial intelligence in favor of a more ‘practical’ application, where results were more noticeable. Fortunately, however, cybersecurity specialists were quick to realize the staggering security potential that AI had and ended up collecting valuable insight into how the tech could virtually revolutionize the cybersecurity landscape.
With the advent of AI-centric cybersecurity tools and products, the security process has become extraordinarily streamlined and relies on minimal to zero input from humans. Along with automating detection and response processes, AI also equips organizations with the ability to concur with a timely response, which cuts on the finances devoted to cybersecurity.
To further demonstrate the lucrativeness of artificial intelligence implementation within the cybersecurity hemisphere, we’d like to go through some of AI’s application in cybersecurity, which includes the following:
Email Scanning
With emails being the primary delivery technique for malicious links and attachments, cybersecurity specialists need to devise ways to detect corrupted emails before they infiltrate an organization’s security infrastructure. Fortunately, the power of artificial intelligence can be harnessed to detect phishing emails as well.
AI, combined with machine learning capabilities, proves to be an excellent means to detect phishing emails since they perform an in-depth inspection of the email. Moreover, the combination of anti-phishing tools with AI allows for simulation clicks on sent links, which ultimately points towards phishing signs, which may be present in any sender feature, including attachments, links, etc.
Combining AI with Antivirus Products
Although cybersecurity analysts focus on harnessing the power of artificial intelligence to formulate new cybersecurity tools, amalgamating AI with antivirus tools can play a pivotal role in identifying anomalies present within the network or the system.
Moreover, combining AI with antivirus products can also help enterprises combat malware programs using machine learning tactics. Once the AI algorithm has learned how legitimate programs interact within the organization’s digital infrastructure, an AI antivirus solution can quickly detect malware programs and drive them out of the system before the malware has accessed any system resources.
Modeling User Behavior
Another real-time application of artificial intelligence in the cybersecurity world is when organizations and companies use AI to monitor and, consequently, model their system users’ behaviors. This practice comes extremely handy when an organization is faced with a takeover attack. A cybercriminal gains access to an employee’s credentials and uses these to wreak havoc on a company. Using a reliable username generator can also be useful in preventing any uncertain situation.
As more and more time elapses, AI learns of the user activities and sets the benchmark for what browsing habits constitute the norm for most users on the network. Suppose a hacker gains access to an employee’s credentials and leverages it to carry out cybercrime. In that case,- AI-powered systems can identify the unusual activity patterns and immediately alert the system admins of the suspicious activity.
Increased Automation
Although we have skimmed over this above, AI can increase the automation of specific processes within an organization, which results in both time and money being saved. Furthermore, along with the automation of menial processes, AI can also play a critical role in system analysis.
Owing to the whopping amount of data generated by user activities, manually analyzing the task is nearly impossible to fulfill. Fortunately, with AI stepping in, system analysis can take place without the need for human input. Moreover, since the AI-powered system continuously monitors the network, malicious agents have a much higher chance of getting detected.
The Darker Side of AI
We will now discuss some of its more sinister aspects. As we’ve already mentioned, as the digital landscape welcomes an increasing number of technological advancements, so does the threat landscape. With rapid progress in the cybersecurity arena, cybercriminals have turned to AI to amp up on their sophistication.
One such way through which hackers leverage the potential of artificial intelligence is by using AI to hide malicious codes in otherwise trustworthy applications. The hackers program the code in such a way that it executes after a certain period has elapsed, which makes detection even more difficult. In some cases, cybercriminals programmed the code to activate after a particular number of individuals have downloaded the application, which maximizes the attack’s attack’s impact.
Furthermore, hackers can manipulate the power offered by artificial intelligence, and use the AI’s ability to adapt to changes in the environment for their gain. Typically, hackers employ AI-powered systems adaptability to execute stealth attacks and formulate intelligent malware programs. These malware programs can collect information on why previous attacks weren’t successful during attacks and act accordingly.
And if that wasn’t enough, hackers leverage AI to devise malware that is capable of mimicking trusted security components. Typically, these trusted security components contain information such as the company’s computation environment, preferred communication protocols, patch update cycles, etc. Not only does an AI-enabled malware make for almost undetectable attacks, but it also allows cybercriminals to launch lethal stealth attacks on an organization.
Final Words
At the end of the article, we can only hope that we’ve presented to our readers a new look into both sides of the AI spectrum. Instead of pretending that AI is some messiah that can’t be tampered by cybercriminals, enterprise owners need to be prepared. With advances in AI, it can only be assumed that technology is a crucial facilitator of multiple cyberattacks in the future!
If machine learning models predict personal information about you, even if it is unintentional, then what sort of ethical dilemma exists in that model? Where does the line need to be drawn? There have already been many such cases, some of which have become overblown folk lore while others are potentially serious overreaches of governments.
fastcore: An Underrated Python Library; Goodhart’s Law for Data Science and what happens when a measure becomes a target?; Text Mining with R: The Free eBook; Free From MIT: Intro to Computational Thinking and Data Science; How to ace the data science coding challenge
The Johns Hopkins SAIS MA in Global Risk (online) program prepares graduates to gain experience analyzing and addressing real-world scenarios, and the knowledge to fine-tune your analyses with insights from economics, history and political science. Enroll now and join a highly active, international community of more than 230,000 Johns Hopkins alumni.