365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
While I was scrolling on Twitter. I saw a tweet showing the word “deep learning” is plateauing on google trends. Then Yann LeCun replied that it’s simply deep learning because become more normal.
This reminds me of a previous blog post that I wrote. Talking about how good tech is like good design. Meaning when technology is good. It embeds itself in our society and becomes invisible. Gmail’s smart compose feature is 100% deep learning. But we don’t think about it as ML. Amazon’s recommendations are ML. But we don’t think about them that way. In normal discourse, we just simply call them algorithms. Which is an accurate term. While abstracting away most of the advanced details.
This makes sense, as only nerds care about the type of algorithm. To recommend films on Netflix. Its recommendation systems. Everybody else will simply just say technology. Or treat the company as a person. Like “Netflix sent me this message.” “Facebook showed me this message.” Etc. When aeroplanes started getting popular we just said we took a flight to Washington DC. Rather than a mechanical flying device helped travel a couple of miles.
As I write this blog post. I use Microsoft Word’s read-aloud feature. To proofread the blog post. Where a robot voice reads why to work for me. The voice has improved tremendously. While it still has some robotic feels to it. It does a good job. It’s like an editor is personally reading my work. Also, I use the program Grammarly. While they do not say it I’m pretty certain they use machine learning. To spot mistakes in your work. These very useful tools that help me improve my writing are drive-by machine learning. Even though people will simply just call it technology.
Big Data Jobs
Just Becuase It Has Hype Does Not Mean Its Useful
This is the cycle of all technologies. You have hype. Depending on how good the technology is. It fails to even go into the mainstream. And start again in the hype cycle. If it’s good. It will fall below expectations not because it’s bad. But failed to meet the sky-high expectations. Afterwards, people start to work out more practical uses of the technology. After a while, the technology gets popular. But lots of the hype starts to fade away. As people get used to the technology. So I guess deep learning or machine learning. The hype is starting to disappear, but people are finding uses for the technology.
You will have some standouts like GPT-3 and GANs. But most machine learning in the wild right now is a little bit boring. Recommendation systems. Think of Netflix and Amazon. Forecasting. Using past data. To predict future behaviours. It tends to be boring as its simply showing other data points based on past data. Or in amazon cases using the AI to help sell more products. Which is no surprise if your for-profit company. You need to make money.
While ML has its limits. I still think is very popular because it can do so many things. Like generating image via GANs. Classifying images with CNNs. To predicting past behaviour using forecasting. I think this is why AI is very popular. Because if you have some type of data. Which in the internet age, the answer is always a yes. Like early computers where it efficiently changed every industry either via automation or communication. With machine learning. It can help with those areas even more.
There is no “Car-based companies” nor “Wi-fi based companies”
In the good tech is like good design blog post. I talked about technology tends to be popular when people stop noticing it. Which is happening now.
In the article I said:
No one calls their company “Excel-based” or “Windows-based”. As it’s [just] a tool.
When people started using office services on their computers. It was revolutionary at the time. But people now, don’t call themselves an “Excel-first company” Or an “email first company”. As people got used to them, people assume that using these services is a given. Soon having some type of data science role will be a given. Just like having a web developer for your company is a given. This will still mainly be focused on tech companies. But non-tech companies are not far behind. Non-tech companies hire web developers and server managers.
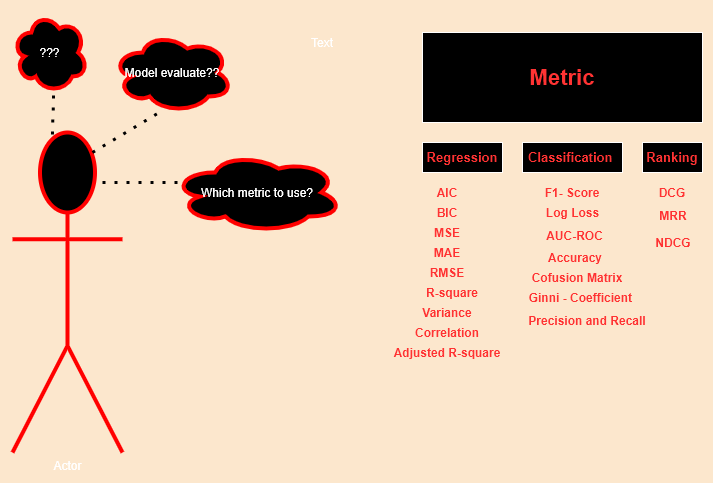
Before getting deep into artificial intelligence, it is important to understand which model should deploy? what are the metrics with respect to dataset and the application of model.
Like a Teacher with the model as our students, there are some parameters or we can say benchmark — decides the quality of our model whether the given model will be selected or it will be rejected.
Below is the brief classification of the metrics which we will be discussing in this as well as the upcoming part.
Fig. 1. Metrics
In this part i.e. part 1 we are going to cover varoius metrics. So without any further delay lets start.
Before boarding, let assume that we have trained one regression model whose name is Learned_Model and after training it gives output as “O” (predicted)for n sample and for “n” number of sample it gives n*O, whereas we have actual output denoted as “Y”(target variable) for n sample,
Big Data Jobs
1. MAE (Mean Absolute Error)
MAE is we break this we will have three separate words i.e. Error, Absolute, and Mean (traversing right to left) where,
Error is the difference between the target and predicted value i.e. Y-O
Absolute is defined as the absolute value of the error i.e. |Y-O|, let it be AE
Mean is defined as taking the average of the Absolute error for n sample
i.e∑ AE /n(AE), where n(AE) is number of sample i.e. n.
Similarly, if we break MSE this we will have three separate words i.e. Error, Square, and Mean (traversing right to left) where,
Error is the difference between the target and predicted value i.e. Y-O
Absolute is defined as the absolute value of the error i.e. (Y-O)², let it be SE
Mean is defined as taking the average of the Absolute error for n sample
i.e ∑ SE/n(SE), where n(SE) is number of sample i.e. n.
Fig. 3 MSE
Note MAE in robust to the outlier than MSE because by squaring the error, the outliers — a high error that other samples get more attention and dominance in the final error hence impact the model parameters.
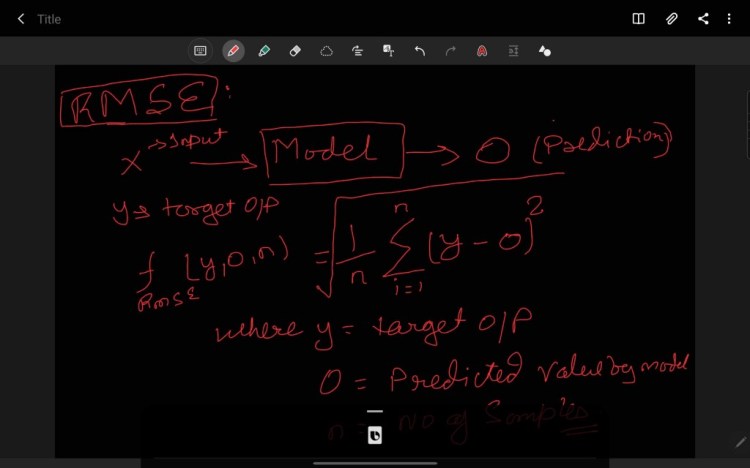
Similarly, if we break RMSE this we will have three separate words i.e. Error, Square, Mean, and Root (traversing right to left) where,
Error is the difference between the target and predicted value i.e. Y-O
Absolute is defined as the absolute value of the error i.e. (Y-O)², let it be SE
Mean is defined as taking the average of the Absolute error for n sample
i.e ∑ SE/n(SE), where n(SE) is number of sample i.e. n.
The root is defined as taking the root of the MSE i.e ( ∑ SE/n(SE))^(1/2)
RMSE is highly affected by outliers. In RMSE the power of root empowers it to show a large no. of deviations. As compared to MAE, RMSE gives higher weightage and punishes large errors.
Fig. 4 RMSE
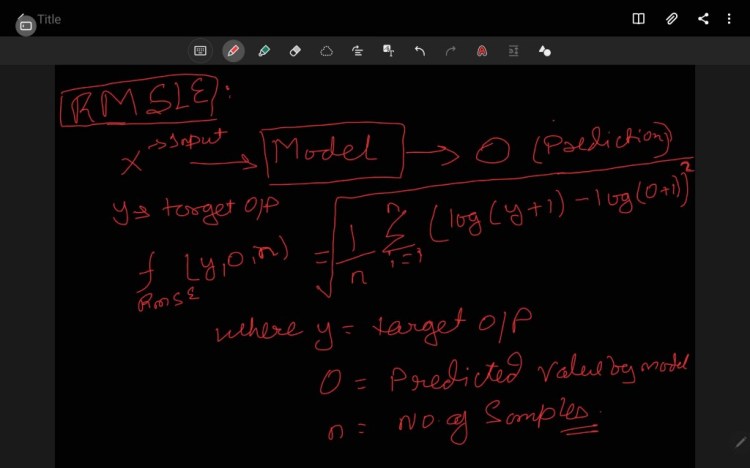
RMSLE denotes Root Mean Square Logarithm Error a derivative of RMSE which scale down the error. Basically it is used when we don’t want to penalize the huge difference in the predicted (Y) and the target value(O), when the predicted value (O) is True Positive i.e. correct.
If both O and Y values are small: RMSE == RMSLE
If either O and Y values are big: RMSE >RMSLE
If both O and Y values are big: RMSE >RMSLE — almost negligible.
R² is also known as the coefficient of determination used to determine the goodness of fit I .e.shows how well the model fits the line or shows how data fit the regression model. Basically it determines the proportion of variance in the D.V that can be explained by I.V. Generally higher the value of R² better the model performs but in some cases this thumb rule also fails to validate. So, we need to consider the other factors also along with the R².
In simple words, we can say how good is our model when compared to the model which just predicts the mean value of the target from the test set as predictions.
As we have discussed R² above, similarly Adjusted R² is an improvised version of the R².
R² is biased it means if we add new features or I.V if does not penalize the model respective of the correlation of the I.V. It always increases or remains the same i.e. no penalization for uncorrelated I.V.
Fig. 7 Problem with R²
In order to counter this problem of non-decrement of R² value, a penalizing factor has been introduced which penalizes the R².
Theoretical intuition of Adjusted R² refer below image:
Fig. 8 Adjusted R² theoretical intuition.
Mathematical intuition of Adjusted R² refer below image:
In Decision trees, the inverse variance is defined by the homogeneity of the node i.e. less the variance more the homogeneity, and hence purity of the node is increased. Variance is used to decide the split of the node which has continuous samples.
The larger the spread of the tail larger the dispersion hence variance is large in terms of Normal Distribution.
AIC refers to Akaike Information Centre is a method for scoring and selecting a model, developed by Hirotugu Akaike.
AIC shows the relationship between Kullback-Leibler measurement and the likelihood estimation of the model. It penalizes the complex model less i.e. it emphasize more on the training dataset by penalizing the model with an increase in the IV. AIC selects the complex model, the lower the value of AIC better the model.
AIC= -2/N *LL + 2*k/N, where
N= No. of Samples in training,
LL=LogLikelihood of model
K= no. of parameters in training dataset.
For mathematical explanation refer to this image.
Fig. 11 AIC Mathematical Intuition and 2nd order of AIC
BIC is a variant of AIC known as Bayesian Information Criterion. Unlike the BIC, it penalizes the model for its complexity and hence selects the simple model. The complexity of the model increases, BIC increases hence the chance of the selection decreases.
BIC = -2 * LL + log(N)*k, where
k= no. of parameters,
LL= logLikelihood,
N= No of sample in training dataset.
For mathematical explanation refer to this image.
Fig. 12 BIC Mathematical Intuition
Special Thanks:
As we say “Car is useless if it doesn’t have a good engine” similarly student is useless without proper guidance and motivation. I will like to thank my Guru as well as my Idol “Dr P. Supraja”- guided me throughout the journey, from bottom of my heart. As a Guru, she has lighted the best available path for me, motivated me whenever I encountered failure or roadblock- without her support and motivation this was an impossible task for me.
Contact me:
If you have any query feel free to contact me on any of the below-mentioned options:
Learn about the experiments by MobiDev for transferring 2D clothing items onto the image of a person. As part of their efforts to bring AR and AI technologies into virtual fitting room development, they review the deep learning algorithms and architecture under development and the current state of results.
Eric Siegel’s business-oriented vendor-neutral three course machine learning series is designed to fulfill the unmet needs of the learner, delivering material critical for both techies and business leaders.
During the 21st century, the revolution in data storage techniques reduces the storage cost of the data as a result the amount of data generated is growing exponentially. It is estimated the by the end of the 21st we will have 44 zettabytes of data. Every action we perform generates data viz. click of a button on our phone, social media, and numerous other activities.
Fig 1. Exponential Growth in Data
The algorithm we are using such as Naïve Bayes, KNN clustering, etc. has roots back in the 1960s but due to the technology barrier was not able to implement this algorithm. But in the 21st-century lot of innovation has been taken place — result hardware has been evolved.
“Artificial Intelligence” term was invented by John McCarthy in 1956 at Dartmouth. A.I is basically data-driven which requires a certain amount of data in order to discover the underlying pattern and relation by training. The ML or DL models trains on these data labeled, unlabeled, or observation using reward and try to predict or classify.
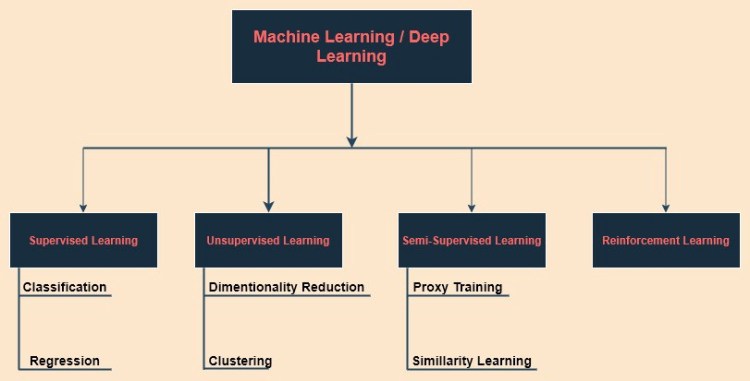
Below are the techniques which are used in ML and as well as DL, classified on basis of the data.
Fig. 2Classification of algorithms based on data
As we have seen in Fig.2 that algorithms are divided in accordance with the data we feed in the model.
Machine Learning Jobs
1. Supervised Learning:
As the name suggests “supervised”, in this the training and as well the testing of the model is done via. labeled example and with ain to minimize the loss function. We all have studied in a school where the teacher used to pinpoint at every alphabet at making us recognize its features until we are not able to recognize the alphabet on our own.
Similarly in a supervised learning algorithm generally dataset is split up into three parts test set, training set, and evaluation set in ratio 70:20:10 respectively. Each dataset is labeled i.e each row is mapped to the corresponding label for example if we are a training a model for the classification of cats and dog each image has its label, these images are sent to the models where forward propagation takes place and then the prediction is made by these models. Then this prediction is used to calculate the loss (using MSE, log loss, and other loss functions) then the loss is propagated backward and weights, as well as biased, are adjusted by doing differentiation of the loss function with respect to bias and weight and using the learning rate the weights are adjusted until the global minimum is reached. In the further section of this, we will be studying these terms in detail with hands-on.
Type of supervised algorithm is Linear regression, Logistic regression, Decision tree, Neural Network, SVM and etc.
Fig. 3 Supervised Learning — Overview
2. Unsupervised Learning
As the name suggests unsupervised means the model extracts the underlying pattern or information from the dataset and group them into clusters. In today’s data-driven era the rate of generation of the data is exponential, while reading this post also you would have generated GB’s of data. So, for such amount of data labeling is very tedious and as well as expensive- an economically timely process.
Here unsupervised learning plays a very crucial role i.e. they discover the underlying pattern and information from the data so that similar data can be grouped together. Unlike supervised learning, no teacher is provided that means no training will be given to the machine. Therefore the machine is restricted to find the hidden structure in unlabeled data by our-self. This algorithm does not have any loss function which helps to backpropagate the errors to adjust the parameters.
Some of the unsupervised algorithms are Isomap, LLC, PCA, DBSCAN, K means clustering, K++ means clustering, Apriori, and various other algorithms.
3. Semi-supervised Learning
In recent years due to the tedious and expensive process — labeling of data a new classification of algorithm came into existence i.e. semi-supervised learning. Supervised learning needs a huge amount of labeled data and unsupervised learning work of unlabelled data which is not accurate as well as needs huge computation. In order to tackle the cons of supervised and unsupervised learning, Semi-supervised learning came into existence.
Semi-supervised learning is a combination of both supervised and unsupervised learning. In this type of learning, the algorithm is trained upon a combination of labeled and unlabelled data. This combination will contain a very small amount of labeled data and a very large amount of unlabeled data. The basic procedure involved is that first, the programmer will cluster similar data using an unsupervised learning algorithm and then use the existing labeled data to label the rest of the unlabeled data.
Some of the semi-supervised algorithms are similarity learning, distance-based learning, etc.
4. Reinforced Learning:
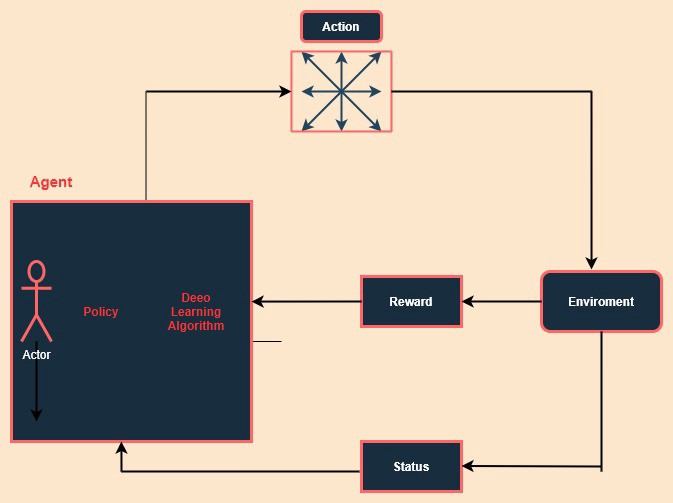
In this learning algorithm, the underlying base of the algorithm is the same i.e Deep Learning is used but here no dataset is given to the network. Instead, the algorithm is composed of Agent, Environment, Reward, Status/observation, and Policy.
The Agent acts on the environment on the principle defined by the respective policy, as a result, the environment gives reward to the agent, and the status of the environment changes. This process is repeated several times until the agent is able to take the correct and necessary decision with respect to the status or his observation on the environment in order to increase the reward count.
Type of supervised algorithm is the Markov process, Q-Learning, DQNN, and various other algorithms.
Fig. 4 RL -OverviewFig. 5 RL — example of pole balancing
Jovian.ml
During our initial stages, we have face several environmental issues i.e. how to run scripts where to run and what packages need to be install. As discussed in the blog how to set up the environment with jupyter notebook.
Jovian.ml is a platform that enables us to share our notebook. Jovian ipython notebook is compatible with Google Colab, Kaggle, and Binder. Binder is a server on which we can run the normal python scripts i.e. without jupyter whereas Kaggle and Colab are the environments that provide us free GPU. We can use Jovian.ml by creating an account and accessing its API. For a basic tutorial follow this link and jovian.ml docs.
Special Thanks:
As we say “Car is useless if it doesn’t have a good engine” similarly student is useless without proper guidance and motivation. I will like to thank my Guru as well as my Idol “Dr P. Supraja”- guided me throughout the journey, from bottom of my heart. As a Guru, she has lighted the best available path for me, motivated me whenever I encountered failure or roadblock- without her support and motivation this was an impossible task for me.
Abbreviations:
AI: Artificial Intelligence ML: Machine Learning DL: Deep Learning Model: The algorithm we use in deep learning or Machine learning such as linear regression, NN, CNN is known as models and training data is fitted into this model for prediction or classification.
Contact me:
If you have any query feel free to contact me on any of the below-mentioned options:
Hello folks, If you are a beginner Python developer and looking for the best courses to learn Artificial Intelligence with Python then you have come to the right place. Earlier, I have shared the best data science courses and best machine learning courses and In this article, I will share the best Artificial Intelligence courses for Python developers to learn AI basics as well as some hands-on courses to practice AI with the Python library.
Artificial Intelligence is one of the growing fields in technology and many developers are trying to learn Artificial Intelligence to take their career next level.
I first come across AI when DeepMind beat Garry Kasparov, one of the finest players of Chess. It was way back in the 1990s, and AI has come a long way since then. Now, Google is using the same DeepMind to reduce electric bills of its Data Center by 40%, and Elon Musk is talking about Self driving cars.
If you are a tech geek or a programmer, these are some of the fascinating examples of Artificial Intelligence, and every time I hear an AI story, I really get hooked up. While all these are good and interesting, as a programmer, I am also spending some time on how to code AI?
Machine Learning Jobs
I am not talking about big problems, but just learning how to use AI for your benefits or customize Artificial Intelligence for your own need will go a long way in the near future, and I am learning all these by joining the online courses and looking at agents on sites like Open AI gym.
If you don’t know, Open AI Gym is a project backed by entrepreneurs like Elon Musk. It provides a toolkit for developing and comparing reinforcement learning algorithms. It supports teaching agents everything from walking to playing games like Pong, Goes, Doom, Breakout, or Pinball.
Since Games are my other interest area, If you don’t know, I learned to code by writing games like Tic-Tac-Toe, Breakout, Tetris, and Chess, developing AI to build games seems a great idea to learn Artificial Intelligence.
If you look closely, games provide a perfect environment for building Artificial Intelligence. When you have an algorithm that can beat the game, you know that the same principles can be applied to solve real-world problems. This is precisely the approach many tech giants like Google and Tesla follows.
If you are like me and want to learn AI or Artificial Intelligence in 2020 with Python and looking for some excellent online courses, then you have come to the right place. In this article, I am going to share some of the best online courses to learn Artificial Intelligence with Python in 2020.
My Favorite Artificial Intelligence Courses for Beginners
There are many courses to learn Artificial Intelligence on the Internet, but most of them are boring or too technical, even for programmers with years of experience.
Since I always believe in simplicity and exciting stuff, I have only chosen a course which has the right mix of theory and practice. These are the courses that not only teach you how to build Artificial Intelligence but also inspire you to learn AI.
Andrew Ng is one person who has inspired millions of developers about Artificial Intelligence and Machine learning through his classic machine learning courses. He is also the founder of Coursera, lead of Google Brain, Chief Scientist of Baidu, and instructor of the most popular Machine Learning course on the planet.
If you are wondering if this is true? Yes, The Machine Learning course on Coursera has been taken by more than 2.6 million students which makes it a popular course on Machine learning. You can check numbers by yourself.
When Andrew Ng announced this course on Twitter, I knew this is something I must join, even though I have attended a couple of classes on Artificial Intelligence, I learned a lot from this course.
This course provides a comprehensive overview of what AI is and the meanings of various concepts being talked about in the context of Artificial Intelligence. It helps you to build your vocabulary so that you can discuss AI with fellow programmers and other people, both online and offline.
This course provides a non-technical perspective of AI, but you can also take this course to learn the business aspects of AI. If you want to build an AI strategy for your company or want to work with an AI team, join this course.
By the way, if you find Coursera courses useful, then I also suggest you join the Coursera Plus, a subscription plan from Coursera which gives you unlimited access to their most popular courses, specialization, professional certificate, and guided projects. It cost around $399/year but its complete worth of your money as you get unlimited certificates
This was the first course I took for learning Artificial Intelligence, and it was no brainer because I am a massive fan of instructor Kirill Eremenko and his SuperDataScience team.
Having attended his in-depth learning course, I know how engaging it is, which is my primary requirement, given the complexity of the subject. I didn’t want to get bogged down by heavy use of Mathematics and neural networks, instead, I wanted a course that can inspire me to learn more, and I must say, I wasn’t disappointed.
This course will teach you how to combine the power of Data Science, Machine Learning, and Deep Learning to create powerful AI for Real-World applications like creating AI to beat the game in Breakout, pass a level in Doom and create logic for self-driving cars.
The course material is really engaging and exciting, especially if you like games and if you haven’t attended any AI course before, I suggest you join this one. You won’t regret it.
Talking about social proof, more than 101,411 students have already enrolled in this course, and it has, on average, 4.4 ratings from 11,452 ratings, which is just phenomenal. A big thanks to Kirill Eremenko and his entire SuperDataScience team for creating this awesome course.
This is another course I have taken on Udemy to learn about how to use AI in games. If you don’t know, Unity is one of the most popular game engines for developing all kinds of video games, and they are using AI to make games difficult depending upon the player’s caliber.
If you are a game designer or game developer and if your non-player characters lack drive and ambition, then you can join this course to learn how to make them more authentic and believable.
In this course, Penny, instructor of the course, reveals the most popular AI techniques used for creating believable character behavior in games using her internationally acclaimed teaching style and knowledge from over 25 years of working with games, graphics, and has written two award-winning books on games AI.
Throughout this course, you will follow along with hands-on workshops designed to teach you about the fundamental AI techniques used in today’s games. If you love video games and want to learn more about how AI is used there, this is the course for you.
This is another fantastic course to learn about Artificial Intelligence in Coursera. In this course, you will learn what Artificial Intelligence (AI) is, explore use cases and applications of AI, understand AI concepts, and terms like machine learning, deep learning, and neural networks.
You will also be exposed to various issues and concerns surrounding AI, such as ethics and bias, & jobs, and get advice from experts about learning and starting a career in AI.
You will also demonstrate AI in action with a mini-project, and get a certificate after completing the project successfully
This course does not require any programming or computer science expertise and is designed to introduce the basics of AI to anyone, whether you have a technical background or not.
If you don’t know, Reinforcement Learning is a big part of AI, and this course provides a complete guide to Deep Reinforcement Learning. It helps you to understand reinforcement learning on a technical level.
It also helps you to understand the relationship between reinforcement learning and psychology.
Reinforcement learning has recently become famous for doing some of the fantastic things in AI like In 2016, we saw Google’s AlphaGo beat the world champion in Go. We saw AIs playing video games like Doom and Super Mario.
Much like deep learning, a lot of the theory was discovered in the 70s and 80s, but it hasn’t been until recently that we’ve been able to observe first hand the amazing results that are possible.
Talking about social proof, this course has been trusted by more than 28,000 students, and it has, on average, 4.6 ratings from close to 5,000 participants, which is just phenomenal. If you are looking for a purely technical course in AI, this is the one to join.
That’s all about some of the best Artificial Intelligence courses for beginners in 2020. I have tried to include some non-technical courses on Artificial Intelligence like AI for EveryOne by the great Andrew Ng, just to understand the business and general aspect of AI, which is far more important than actually learning how to build AI for a particular domain or problem.
Other Machine Learning and AI Resources for Programmers
Thanks for reading this article so far. If you like Artificial Intelligence or AI best courses, then please share it with your friends and colleagues. If you have any questions or feedback, then please drop a note.
P. S. — If you are serious about moving into AI and Machine Learning field, I also suggest you learn Python, one of the most valuable skills when it comes to Machine Learning and AI. If you need resources, check out this list of best Python courses to kick-start your journey.
Hi, I’m Ken Jee, and in this article, I will share insight on my favorite data use case: sports analytics.
In my day job as the Head of Data Science at Scouts Consulting Group, I help improve the performance of athletes and teams by analyzing the data collected on them. I love my job, and I am excited to join the 365 Data Use Cases series to share 3 ways in which data science is applied in the broader field of professional sports.
You can check out our video on the topic below or scroll down to keep on reading.
Winning the Game with Sports Analytics
Data science has only recently entered the mainstream with sports analytics.
However, it has really been around since the early 2000s. The most popularized example is Michael Lewis’s book “Moneyball” which also has a movie adaptation. In the book, the Oakland Athletics face massive salary cap cuts. So, they needed to be very efficient with their spending. The protagonist, the team’s general manager Billy Beane, had to figure out a way to win without access to star players.
In reality, this is one of the main ways we currently use data science in sports – to help a team generate the most wins with the budget constraints that they have.
To cut the long story short, thanks to data science and sports analytics, the Oakland A’s had an incredible playoff run that year, well beyond what could have been expected with the budget they had at their disposal.
At the time, being interested in players that seemingly no one else wanted was extremely against the grain. But, in all honesty, there is still some of this sentiment in professional sports. Sports are inherently traditional and there are still a lot of superstitions involved. So, many people are uncomfortable with the new insights that data science provides. On the other hand, it looks like the teams that don’t adopt the data will start racking up losses at an alarming rate.
Sports Analytics and Fan Engagement
Another way that data science can be used in sports is on the fan engagement side. It is rare that you will see a broadcast without some statistics sprinkled into the dialogue or a fascinating data visualization plastered on the screen.
People often forget that data science is about storytelling. And we can use the data to give fans a better understanding of the game and make them more engaged with the content.
In fact, fans are constantly finding new ways to engage with live events, and one of the most unique ways is through fantasy sports.
Fantasy sports in and of itself is almost a $20 billion market. So, it’s not surprising that there is a tremendous number of websites specializing in how you pick your own team and optimize your roster.
Sports Analytics for Game Outcome Prediction
This takes us to the third way data science is used in sports: predicting game or player outcomes. In 2018, the Federal Government legalized sports betting federally. This means that each individual state now has the right to allow it and set up regulation around it. This change brought a boom in interest in using data to predict the outcomes of games.
Both the fans and the people running the sports books are constantly trying to improve their models to make a little extra money. In my opinion, this as a huge area for the growth of data science in sports. The question is: “Can your model predict game outcomes better than the average person?”
The Future of Data Science and Sports Analytics
Teams now have access to incredible amounts of data that they have only begun to sift through. Both the NBA and the NFL have tracking data that allows teams to know where all the players and the ball are on the court at any given millisecond.
The trend is for teams, fans, and companies to look at sports data at an increasing rate.
We are just beginning to understand what is possible with all of this data, and I believe you can be a part of this discovery process, too.
I hope you enjoyed reading this article. Check out my YouTube channel if you want to learn more about sports analytics and how to break into data science. Looking to start a career in data science? Sign up for my course where I guide you through all the steps to landing a data science job. You’ll learn how to create your data science project portfolio, build your resume, get an interview through networking, succeed during the phone interview, solve the take-home test, and ace the behavioral and technical questions.