Our focus for this piece is to establish the best practices that make an ML project successful.
Originally from KDnuggets https://ift.tt/36YSdg2

365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Originally from KDnuggets https://ift.tt/36YSdg2
Usually in any K-means clustering problem, the first problem that we face is to decide the number of clusters(or classes) based on the data. This problem can be resolved by 3 different metrics(or methods) that we use to decide the optimal ‘k’ cluster values. They are:
Let us take a sample dataset and implement the above mentioned methods to understand their working.
We will use the make blobs dataset from sklearn.datasets library for illustrating the above methods
Now let’s look at what these methods area and that after implementing those three methods on the created dataset what are the results.
A) Elbow Curve
The main idea is to define clusters such that the total within-cluster sum of square (WSS) is minimized. It measures the compactness of the clustering and we want it to be as small as possible. The idea is to choose a number of clusters (k) so that adding another cluster doesn’t improve much better the total WSS.

***What Within-cluster Sum of Square mean (WSS)?
Basically it is the sum of squared distance (usually Euclidean distance) from it’s nearest centroid (center point of cluster).
It decreases with increasing number of clusters(k). Aim is to find the bend (like an elbow joint) point in the graph.
1. Fundamentals of AI, ML and Deep Learning for Product Managers
3. Graph Neural Network for 3D Object Detection in a Point Cloud
4. Know the biggest Notable difference between AI vs. Machine Learning
***This method is called elbow curve because the visual representation of the WSS w.r.t. the number of clusters(k) looks like human elbow
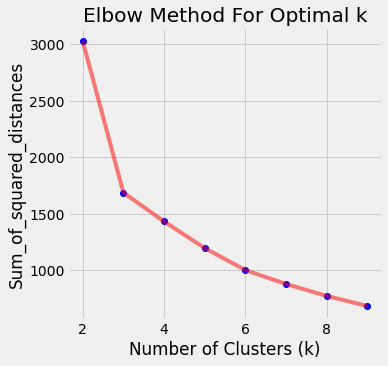
Here, we find that the k=3 is the bend(elbow) point.
*** Usually elbow curve method is a little ambiguous as the bend point for some datasets is not visible clearly
B) Silhouette Score
Silhouette Score is calculated using mean of intra-cluster distance (a) and the mean of nearest-cluster distance (b) for each sample. The Silhouette Coefficient for a sample is (b -a) / max(a, b). For better clarification, intra-cluster distance (a) is distance of sample point to it’s centroid and (b) is distance of sample point to nearest cluster that it is not a part of. Hence, we want the silhouette score to be maximum. Thus, have to find a global maxima for this method.
Silhouette coefficient exhibits a peak characteristic as compared to the gentle bend in the elbow method. This is easier to visualize and reason with.

Here, we can easily visualize the peak point at k=3.
C) Davies Bouldin Index
It is defined as a ratio between the cluster scatter and the cluster’s separation. Basically a ratio of within-cluster distance and between cluster distances. Aim is to find optimal value in which clusters are less dispersed internally and are farther apart fro each other (i.e. distance between two clusters is high). Hence, a lower value of Davies Bouldin index will mean that the clustering is better.
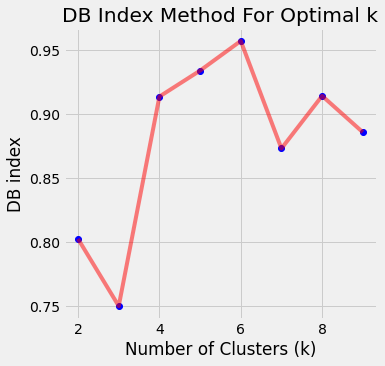
As I mentioned earlier lower value is desired, so we find the global minima point i.e. k= 3.
So after using all the above mentioned methods, we concluded that optimal value of ‘k’ is 3. Now, implementing the k-means clustering algorithm on the dataset we get the following clusters.
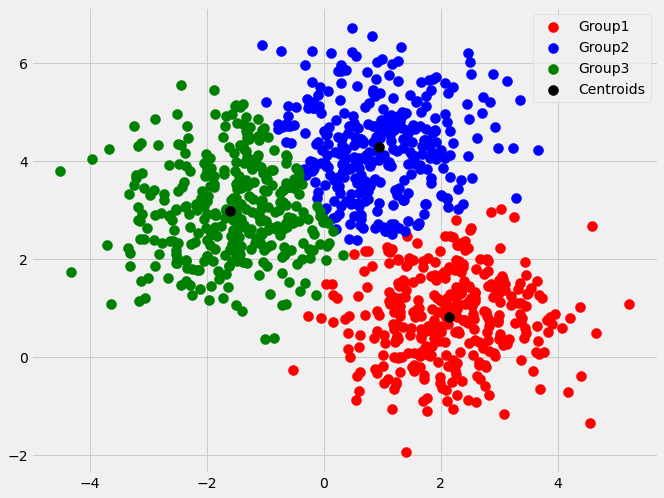
We can see from the above graph that all points are classified into three clusters appropriately. Hence, the k=3 was an optimal value for clustering.
You can find the entire code snippet at GitHub location here: https://github.com/kavyagajjar/K-Means-Clustering/blob/main/K-means-Make_blobs/Optimal_K_using_k_means_clustering.ipynb




3 minute read to ‘How to find optimal number of clusters using K-means Algorithm’ was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.

In the future, I see operators guiding groups of algorithms: it will be a time when machines will be able to generate their own knowledge based on human-produced frameworks … Human plus machine means finding a better way to combine better interfaces and better processes
— Gary Kasparov (Chess Grandmaster)
There is a lot of value in using intelligent systems to improve the quality of our work. For text analysis our best AI algorithms are still lacklustre (in spite of what some headlines may tell you about work like GPT-3). Perhaps one day an algorithm could take all of your qualitative research notes and summarise them for you. For now we have to rely on other approaches.
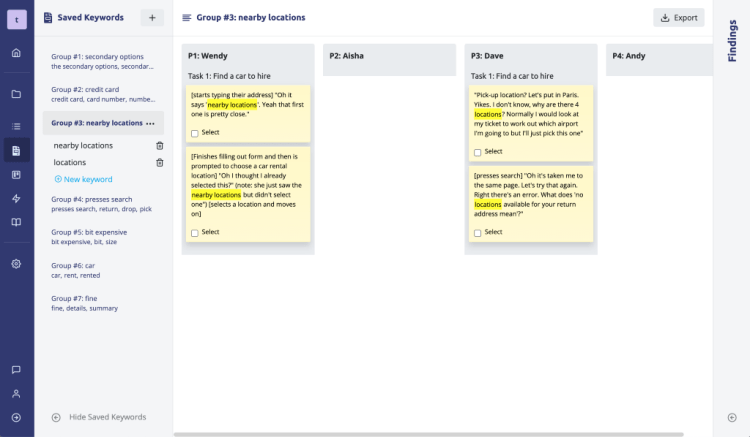
At Evolve we’ve been looking at using Machine Learning to speed up the process of analysing UX research. Our latest approach is to use Natural Language Processing to kickstart the research process rather than to try to replace it.
We’ve experimented with a lot of approaches including complex algorithms involving neural networks. The complex approaches didn’t generate particularly impressive results and we’ve found that a simple algorithm actually worked best.
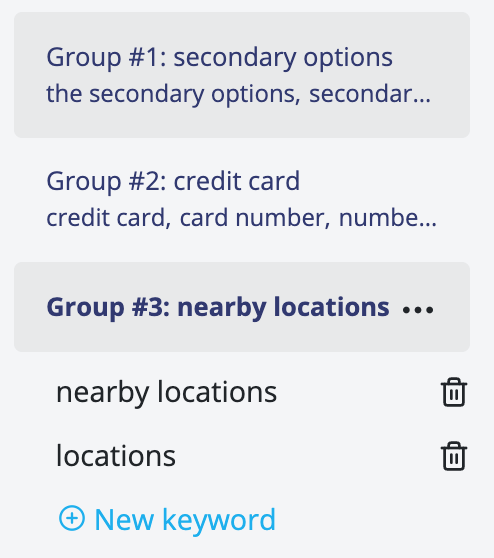
Our approach is simple:
The algorithm isn’t perfect. But given that the algorithm can analyse a typical UX research project in a couple of seconds its results are generally useful.
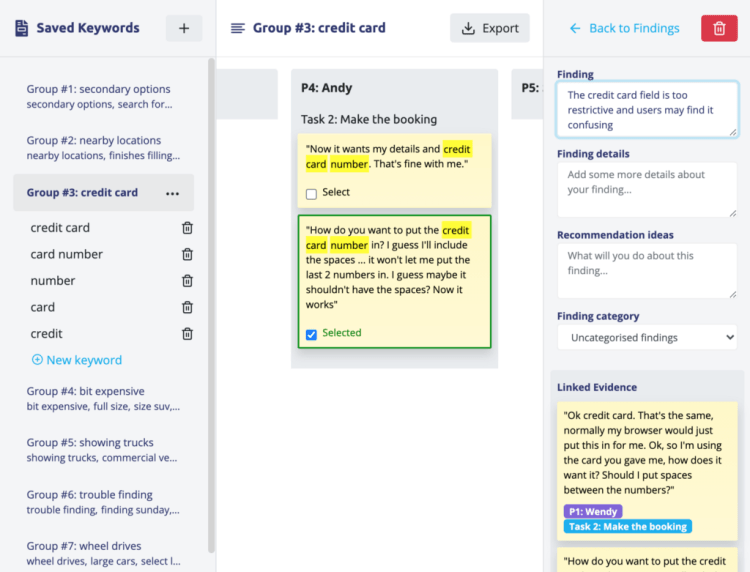
The most useful aspect of this approach is that it can help fast-track the analysis process. We want users to be actively engaged in the research process rather than relying on an algorithm to analyse their research for them.
If the algorithm adds incorrect keywords to a group — remove them. If it misses an important keyword — add it. If there is a topic that you feel isn’t covered — create one.
1. Fundamentals of AI, ML and Deep Learning for Product Managers
3. Graph Neural Network for 3D Object Detection in a Point Cloud
4. Know the biggest Notable difference between AI vs. Machine Learning
From there it’s about finding patterns and interesting observations in the data. With this approach it should be easier to identify research findings by only looking at a subset of the data.
At this stage we’re looking for feedback on whether or not this is useful in analysing the UX research process. The Evolve UX Research app has a completely free plan and our paid plan is free while we’re in beta. If you have any feedback on this approach we’d love to hear it.
Can machine learning speed up UX research analysis? was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
“Perl was designed to work more like a natural language. It’s a little more complicated but there are more shortcuts, and once you learned the language, it’s more expressive.”

When I initially heard of the term Natural Language Processing, I was like “Wait what….. how is it possible that machines can understand and interpret what we say”. Then after a few google searches, I came to know that it is nothing but a lot of text data and maths.
Natural Language Processing is divided into:-
So, Today we are going to talk about the Easiest one “Sentiment Analysis”.
Sentiment Analysis is an analysis technique to get the emotions of the person by the text he wrote.
Eg:-
“This Place is not Good” This line has a Negative Sentiment.
“This Place is Good” has a Positive Sentiment.
So Predicting these Sentiments is called Sentiment Analysis. It can be of more types like happy or not happy, Happy Angry or Surpised.
Coming to The Practical Part:-
→ First is the Collection of data.
→ Removing the Punctuations in the Text, But removing punctuations is not always good because it also carries emotions in text, so it totally depends upon the user and data what is it representing.
→ Removing Stop Words from the Text like “and, or, etc”, as it doesn’t carry any sentiment with it.
→ Stemming of the data, Stemming of text is “Stemmers remove morphological affixes from words, leaving only the word stem.”
eg:- Working, Worked, Work →(Stemming) →Work
here you can see that all the words carry the same meaning with it so including all the terms in our dictionary will make our model slow, instead, we can stem the words and replace them with their stemmed words.
1. Fundamentals of AI, ML and Deep Learning for Product Managers
3. Graph Neural Network for 3D Object Detection in a Point Cloud
4. Know the biggest Notable difference between AI vs. Machine Learning
Here Your Data PreProcessing is Complete…….
From here 60% of your work is complete.
Now What you have to do Is to Create a Frequency Table of Repetition of words in your text. Don’t worry Tfidf Vectorizer will do the work for you in one line of code just initialize it and run it with your text data.
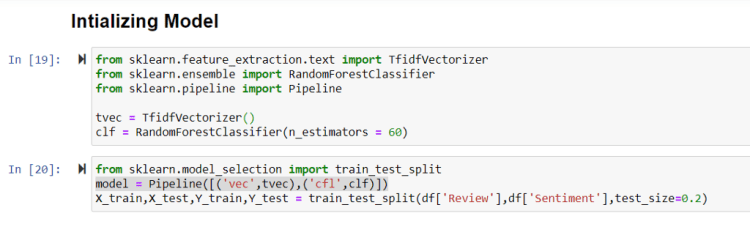
Here this will create your Frequency table of words with the Sentiment it carries, Create a Pipeline with your preferred Classification Technique, and Tfidf Vectorizer.
Train the Model with your Text Data and Check With Test Data….. That’s all. 🙂
My Jupyter Notebook for This Sentiment Analysis:-
harsh674/Sentiment-Analysis-of-Financial-News
Sentiment Analysis in 3 Minutes, Intro to Natural Language Processing. was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.
Originally from KDnuggets https://ift.tt/2GH80Wg
source https://365datascience.weebly.com/the-best-data-science-blog-2020/how-to-be-a-10x-data-scientist
Originally from KDnuggets https://ift.tt/3lH9VsH
Originally from KDnuggets https://ift.tt/2GV30Nh

Vladimir Ninov is a marketing professional and Head of Organic Growth at 365 Data Science with rich experience in PR, growth hacking, and fintech. He holds a Master’s degree in Business Administration and has founded several companies, including a consultancy firm, a PR agency, and a digital marketing blockchain startup. Vladimir is also a contributing writer for Forbes and Entrepreneur magazines. He has been a marketing advisor on a wide range of projects, one of which won the CESA award for Best Blockchain Startup in Bulgaria.
Hi, my name is Vladimir and I am a digital marketing ninja and a tech-savvy enthusiast.
I am a part of the 365 Data Science marketing team and also Head of Organic Growth. So far, I’ve worked on numerous social media, SEO, and organic growth initiatives.
My current task is focused on onboarding publishers to our affiliate program. This is an extremely exciting and challenging project because the affiliate marketing sector is an entirely separate segment in digital marketing and the mindset of the individuals in it contrasts greatly with those from other segments.
Well, I obtained my bachelor’s degree in Business Administration with a concentration in Marketing. I also hold a Master’s degree in Business Administration.
Since 2008, I’ve worked in various fields like international trade, recruitment, finance, clinical trials for the pharmaceutical sector, digital marketing, PR, consulting, growth hacking, blockchain, technology, and fintech.
Moreover, for the past 8 years, I have founded numerous companies including a consultancy firm, PR agency, and a digital marketing blockchain startup. In 2018, I received an invitation to join The Oracles and I became a contributing writer for Forbes and Entrepreneur magazines. Since then, I have been a marketing advisor for several fintech and blockchain projects, one of which won the CESA award for Best Blockchain Startup in Bulgaria.
The blockchain space is one of the fastest-growing sectors for the past couple of years. In addition, based on the LinkedIn report “The Most In-Demand Hard and Soft Skills of 2020”, blockchain is the top in-demand hard skill valued by companies.
I think that within the next 5 years, this technology will completely transform the banking and financial sectors. In fact, blockchain is analogous to the booming of the internet, mobile application development, and the launch of debit and credit cards during their era.
In all honesty, although I gain satisfaction in all aspects of my job, the part that excites me the most is the enthusiasm of the 365 team. Everyone is consistently open-minded to exploring new ideas to help progress together in this amazing educational platform.
Something that many people are not aware of is that companies and cryptocurrency exchanges are increasing their use of AI and machine learning algorithms to automate their trading and volumes.
Great question! On a daily basis, I utilize the Brave browser, which I particularly find useful for work, as it blocks ads and web trackers. This permits me to browse safely without interruptions when doing research that involves repetitive ads from websites. Furthermore, I am a big fan of the Mix extension because it allows me to collect articles and return to them whenever I’d like to.
Well, I absolutely enjoy exotic destinations. Hopefully, after the current global pandemic traveling will be back to normal, as I’d love to finally visit my dream destination – Bora Bora.
If I were a transformer, I would transform into a Tesla… Just kidding. I am a huge fan of the Ferrari Enzo.
Yes! They should consider joining the data science field as soon as possible. Back in 2012, Harvard Business Review called Data Scientist to be “The Sexiest Job of the 21st Century”. Nowadays, the demand for data scientists is growing like never before. This entirely novel field will open a new world of opportunities for any digital marketer who desires to enter the data science field.
Vladimir, thank you so much for this interview! We wish you countless exciting 365 projects ahead and tons of bold ideas you set forward and turn into reality!
The post Interview with Vladimir Ninov, Head of Organic Growth at 365 Data Science appeared first on 365 Data Science.
from 365 Data Science https://ift.tt/3nJ2Rh1
Originally from KDnuggets https://ift.tt/3nCylW6
Originally from KDnuggets https://ift.tt/3lwX6AO
source https://365datascience.weebly.com/the-best-data-science-blog-2020/algorithms-of-social-manipulation
