365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Programming languages have long been in existence, and every time you can find new programming languages sweeping away the old one. To stay adept with the latest development in technology, knowledge about a programming language is paramount. One of the programming languages that has garnered a lot of attention in recent times is Python. Whether you want to excel as a Big Data expert or you, want to make your way to become a data scientist, IoT expert, or even an AI expert, Python programming is a must. As per the Stack Overflow survey, Python has taken over conventional programming languages like Java, C, C++. This makes Python certification as one of the most popular certification choices among st the tech geeks. If you, too, are willing to make a career in this field, then we have this blog for you.
Big Data Jobs
Why should one go for Python certification?
If you are from the field of technology, you would have often heard about Python and would be well-acquainted with Python’s popularity. So, what makes Python so popular, and why should you learn it? Let’s explore:
1. Easy to learn- One of the first reasons that make Python a popular programming language choice is that it’s easy to learn. It is a high-level programming language that is blessed with the community. At the same time, it is easy to interpret and is open source. All these features make it a popular programming language choice amongst the developers.
2. Good for web development– Python, is considered suitable for web development. It has an array of frameworks like django, Flask, Pylons, etc. this framework is Python, and hence it becomes easier for those who have knowledge about Python to work on it.
3. Computer graphics– Another reason that adds to Python’s popularity is that it is being used in large and small online or offline projects. Python uses the ‘Tkinter’ library provides an easy way to create applications. Python is also popularly used in-game development to write the logic using the “pygame” module.
4. Big Data- Python can easily handle a large volume of data, and it supports parallel computing where you can use Python for Hadoop. Python has a library, also called “Pydoop,” and with this, you can write a MapReduce program. Python also has other libraries like “Dask” and “Pyspark: for processing Big Data. So, if you wish to become a big data expert, learning about Python certification is a good choice.
5. Data Science- Another area of application of Python is in data science. Python deals with Matplotlib and Seaborn libraries, which are helpful for Data Science.
By now, we have discussed Python’s application; from the above description, you can draw the inference that Python is a highly versatile language that finds a multitude of applications. Once you have learned Python, it becomes easier for you to make your career growth in your chosen field.
So how does it help you in the future? Let’s have a quick gander at the same:
1. Bette salary- Everybody wants to earn well, and one of the ways is to stay abreast with the skills that are in demand in the market. Upskilling yourself and learning a new programming language will surely help you become an expert in your professional world. A Python developer can easily make $123,642 per year. Since Python is a popular programming language, if you master this programming language, you will become a more efficient and expert developer.
2. Give more weightage to your resume– Since Python is the most sought-after programming language, knowledge about the same will give you an upper edge. You can also opt for a Python crash course, which is specially curated for working professionals.
3. It is the fastest-growing programming language– Python is undoubtedly the fastest-growing programming language. As per Codecademy, there was a 34% increase in users studying Python in 2018. As per Stackoverflow.com, Python is the fastest-growing programming language. Its versatile and ease of usage makes it one of the popular choices amongst the developers.
With all these advantages that Python offers, it is undoubtedly reigning a supreme choice amongst both young developers and those who have gained experience in technology.
Better job prospects, better package, and a promising future all these make Python a popular career choice amongst all. So, if you wish to become a Python expert, this is the time to join the Python crash course certification.
Concluding thoughts:
If you are looking for a good learning platform that can provide you all the insight into Python while helping you learn the same practical applications, then Global Tech Council is the right choice. It is a leading platform that offers a blend of both classroom learning and practical learning.
You can opt for an online Python certification course and become an expert in this domain. Connect with the Global Tech Council today.
This article takes a look at the concepts of data privacy and personal data. It presents several privacy protection techniques and explains how they contribute to preserving the privacy of individuals.
Once a Data Scientist, there are certain skills you will apply each and every day of your career. Some of these might be common techniques you learned during your education, while others may develop fully only after you become more established in your organization. Continuing to hone these skills will provide you with valuable professional benefits.
Hi, my name is Viktor – a Hamilton College graduate with a double degree in Mathematics and Economics, and a course creator at 365 Data Science – and I’m delighted to announce the latest addition to our Program: TheData Preprocessing with NumPy Course!
In this brief post, I’ll walk you through the course features, its structure, and the practical skillset it will help you develop. In the end, I’ll share a bit more about myself and the projects I’ve worked on here, at 365 Data Science.
The 365 Data Science Data Preprocessing with NumPy Course
The idea behind this hands-on course is to guide you through one of Python’s most popular packages – NumPy. I’ll explain why it’s so important and help you explore the various applications of the ndarray class in practice.
I did my best to make sure that by the time you complete the course, you’ll be confident working with arrays. You’ll also learn how to manipulate their dimensionality, as well as how to quickly refer to the documentation when in doubt. Furthermore, you’ll be ready to take advantage of NumPy’s various built-in functions and methods to create your own datasets with random data.
I will also teach you how to use the statistical capabilities of NumPy to analyze your data, as well as its preprocessing ones, through filling missing values, shuffling, sorting, and stacking. And, finally, I’ve included a full practical example with a real-world dataset, so you can apply everything you have learned.
Who Is This Course for?
The Data Preprocessing with NumPy course is a perfect fit not only for beginners but for all of you who want to take their Python programming skills to the next level.
What Is the Structure of the Course?
The course comprises 51 lectures, 10 exercises, 2 quizzes, and 26 downloadables. If you’d like to explore all topics in the course curriculum, you can find them on the Data Preprocessing with NumPy course page.
What Will You Learn?
The course will help you develop a myriad of skills necessary to make the most of NumPy in your practice.
You will learn how to:
Install and upgrade NumPy
Make the most of the NumPy documentation
Manipulate ndarrays
Apply conventional, stepwise, and conditional slicing to arrays
Create your own datasets by generating arrays of random and quasi-random data
Access and modify your file system through NumPy and work with npy and npz files
Make statistical computations with NumPy – minimal and maximal values, averages, covariances, correlations, histograms
Clean and preprocess data – find and fill missing values, reshape an array, remove corrupted data, shuffle and sort
Slice and dice your data through stripping, stacking, and concatenating
About the Author
As I mentioned, I hold a double degree in Mathematics and Economics from Hamilton College, New York.
My analytics background stems from my Statistics, Econometrics, Financial Time-Series Econometrics, and Behavior Economics education.
In terms of coding, my experience includes working with C, C++, and Python, as well as MATLAB and STATA. If you’re curious to learn about my experience and projects, you can find more details in this interview.
The Data Preprocessing with NumPy course is part of the 365 Data Science Program, so current subscribers can access the courses at no extra cost.
To learn more about the 365 Data Science Program curriculum or enroll in the 365 Data Science Program, please visit our courses page.
Want to explore the curriculum or sign up 15 hours of beginner to advanced video content for free? Click on the button below.
Introduction to DP with Randomized response example.
Summary: Sometimes knowing the basics is important! This beginner friendly blog post covers a quick and easy introduction to Differential Privacy and is part of “Differential Privacy Basics Series”. Thank youJacob Merrymanfor the amazing graphic used in this blog post. For more posts like these on Differential Privacy followShaistha FathimaandOpenMinedon twitter.
Differential Privacy Basics Series
Before we dive deeper into Differential Privacy (DP) and answer the 4 W’s and an H (What, Where, When, Why and How), few of the most important questions that you must ask yourself are… What is Privacy? Should we really care about it? How does it matter?…
What is Privacy?
As per Wikipedia’s definition,
Privacy is the ability of an individual or group to seclude themselves or information about themselves and thereby express themselves selectively.
To put it simply, privacy is an individual’s right to withhold some of their data which they deem to be private and share the ones they are comfortable with.
Coming to… Should we really care about it? How does it matter?
In this digital age, data privacy has always been a concern for some of us, to the extent that people are paranoid enough to use a made-up names instead of their own! Even if you are not that paranoid, say you are comfortable with sharing your real name with an unknown person as part of your introduction, you might not feel comfortable with sharing some of your other details like birth date, hangout places you love to go to, your hobbies, etc. This is where privacy comes in, the data YOU would want to keep PRIVATE!
Thus,Privacy can also be said to bethe right to control how information about you is used, processed, stored, or shared.
For a better understanding of — why privacy matters? OR Privacy vs Security? I would recommend you to take a short read to the below blog posts:
Differential privacy is asystemfor publicly sharing information about a dataset by describing the patterns of groups within the dataset while withholding information about individuals in the dataset.
Note:Differential Privacy is not an algorithm but a System or Framework described for better data privacy!
One of the easiest examples to understand DP concerning the above definition is, the one stated by Abhishek Bhowmick (Lead, ML Privacy, CORE ML | Apple) in his interview in the Udacity’s Secure and Private AI Course:
(Note: I will be using this course material as a reference throughout the post)
Suppose we want to know the average amount of money an individual holds in his/her pocket to be able to buy an online course? Now chances are, many might not want to give out the exact amount! So, what do we do?!
This is where DP comes in, instead of asking the exact amount, we ask the individuals to add any random value (noise) in the range of -100 to +100 to the amount they hold in their pockets and give us just the resultant sum of it. That is if ‘X’ had 30$ in his/her pocket by adding a random number say -10 to it, (30 + (-10) ), they give us just the result, which is 20$ in this case. Thus, preserving their individual privacy.
To protect the data privacy obtained from the different potential individual, we add noise(the random number like in the above example) to the data to make it more private and secure! DP works by adding statistical noise to the data (either to their inputs or the output).
But, this brings us to another question — How is it useful to us if all we get are some random numbers?
The answer to this is Law of Large Numbers:
The law of large numbers, in probability and statistics, states that as a sample size grows, its mean gets closer to the average of the whole population.
When a sufficiently large number of individuals give their resultant sum values. It is seen that when the average of these statistically collected data is taken, the noise cancels out and the average obtained is near to the true average (average of the data without adding noise (random number)). Thus, we now have data on the “average amount an individual hold in their pocket”, at the same time preserving their privacy.
Key Takeaways:
The law of large numbers states that an observed sample average from a large sample will be close to the true population average and that it will get closer, the larger the sample.
The law of large numbers does not guarantee that a given sample, especially a small sample, will reflect the true population characteristics or that a sample which does not reflect the true population will be balanced by a subsequent sample.
For better understanding of the Law of Large Numbers, refer to the following:
Differential Privacy describes a promise, made by a data holder, or curator, to a data subject (owner), and the promise is like this: “You will not be affected adversely or otherwise, by allowing your data to be used in any study or analysis, no matter what other studies, datasets or information sources are available”.
It sounds like a well thought definition but maybe more of a fantasy — as De-anonymization of datasets may happen!
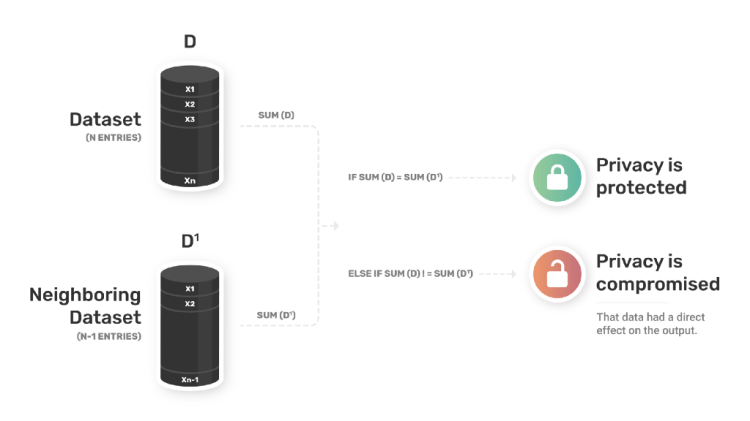
This may lead to a question — How do we know if the privacy of a person in the dataset is protected or not? For example, a database with (1) patients and their cancer status and their information OR (2) a coin flip and their (heads or tails) response!
The key query for the DP in such cases would be,” If we remove a person from the database and the query does not change, then that person’s privacy is fully protected”. To put it simply, when querying a database, if I remove someone from the database, would the output of the query be any different?
How do we check this? By creating a parallel database with one less entry (N-1) compared to the original database entries (N).
Lets take a simple example of coin flips, if the first coin flip is heads say Yes (1) and if its tails then answer as per the second coin flip. So, our database will be made of 0’s and 1’s i.e., a binary dataset. The easiest query that can be thought of with this binary dataset is “Sum Query”. The Sum query will add all the 1’s in the database and give a result.
Assuming, D is the original database with N entries and D’ is the parallel database with N-1 entries. On running the sum query on each of them, if sum(D) != sum(D’), it means the output query actually is conditioned directly on the information from a lot of people in D database! It shows non-zero sensitivity, as the outputs are different.
Sensitivity is the maximum amount that a query changes when removing an individual from the database.
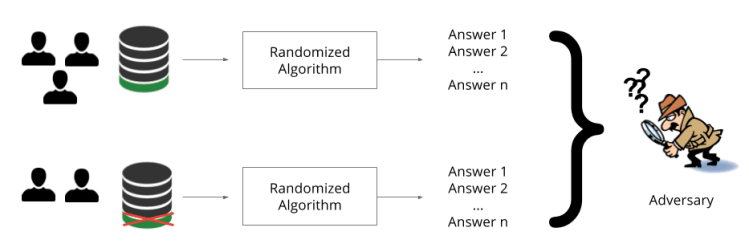
Differential privacy is a framework for evaluating the guarantees provided by a mechanism that was designed to protect privacy. Invented by Cynthia Dwork, Frank McSherry, Kobbi Nissim and Adam Smith [DMNS06], it addresses a lot of the limitations of previous approaches like k-anonymity. The basic idea is torandomizepart of the mechanism’s behavior to provide privacy. In our case, the mechanism considered is always a learning algorithm, but the differential privacy framework can be applied to study any algorithm.
The intuition for introducing randomness to a learning algorithm is to make it hard to tell which behavioral aspects of the model defined by the learned parameters came from randomness and which came from the trainingdata. Without randomness, we would be able to ask questions like: “What parameters does the learning algorithm choose when we train it on this specific dataset?” With randomness in the learning algorithm, we instead ask questions like: “What is the probability that the learning algorithm will choose parameters in this set of possible parameters, when we train it on this specific dataset?”
We use a version of differential privacy which requires that the probability of learning any particular set of parameters stays roughly the same if we change a single training example in the training set. This could mean to add a training example, remove a training example, or change the values within one training example. The intuition is that if a single patient (Jane Smith) does not affect the outcome of learning, then thatpatient’s records cannot be memorized and her privacy is respected.We often refer to this probability as the privacy budget.Smaller privacy budgets correspond to stronger privacy guarantees.
In the above illustration, we achievedifferential privacy when the adversary is not able to distinguish the answersproduced by the randomized algorithm based on the data of two of the three users from the answers returned by the same algorithm based on the data of all three users.
Few good reads to understand De-anonymization of datasets are as follows:
Always Remember — Differential privacy isnot a property of databases, but a property of queries. The intuition behind differential privacy is that we bound how much the output can change if we change the data of a single individual in the database.
So, What DP ‘does’ promises?
Differential privacy promises to protect individuals from any additional harm that they might face due to their data being in the private database x that they would not have faced had their data not been part of x.
By promising a guarantee of ε-differential privacy, a data analyst can promise an individual that his expected future utility will not be harmed by more than an exp(ε)≈(1+ε) factor. Note that this promise holds independently of the individual is utility function ui, and holds simultaneously for multiple individuals who may have completely different utility functions.
What DP ‘does not’ promise?
Differential privacy does not guarantee that what one believes to be one’s secrets will remain secret. That is, it promises to make the data differentially private and not disclose it BUT not to protect it from attackers! Ex: Differential attack is one of the most common form of privacy attack.
It merely ensures that one’s participation in a survey will not in itself be disclosed, nor will participation lead to disclosure of any specifics that one has contributed to the survey.
Do not confuse Security with Privacy, while Security controls “WHO” can access the data, Privacy is more about “When” and “WHAT” can they access .i.e, “You can’t have privacy without security, but you can have security without privacy.”
Security VS privacy
For example, everyone is familiar with the term “Login Authentication and Authorization” right? Here, authentication is about “Who” can access the data and thus, can come under Security, whereas, authorization is all about “What”, “When” and How much of data is accessible to that specific user, thus, can come under Privacy.
That’s all folks! In the next post of this series we will look into the Types of Differential Privacy — Local VS Global DP, with some real world examples.
Till then you may also check out my other beginner friendly Series: