365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Also: 5 Ways to Detect #Outliers That Every #DataScientist Should Know #Python Code; The State of AI and Machine Learning 2020 – Just Released; Top 20 Latest Research Problems in #BigData and #DataScience; Python Libraries for Interpretable #MachineLearning #KDN
In this blog post, learn how to build a spam filter using Python and the multinomial Naive Bayes algorithm, with a goal of classifying messages with a greater than 80% accuracy.
From search engines and sentiment analysis to virtual assistants and chatbots, there are numerous areas of research within machine learning that require text annotation tools and services.
In the AI research and development industries, annotated data is gold. Large quantities of high-quality annotated data is a goldmine. There are a variety of text annotation tools and services available that can provide you with the data you need. Some of these services include entity extraction, part-of-speech tagging, sentiment analysis, and more.
One of the veteran companies in the industry, Lionbridge has over 20 years of experience and over 500,000 expert annotators. With a specialization in linguistics, Lionbridge AI’s crowd staff, fluent in 300 different languages, can annotate your text with accuracy and a quick turnaround. The company is a trusted provider of multilingual data annotation services in the natural language processing field. Some of their text annotation services include text extraction, OCR text correction, linguistic feature tagging, linguistic component analysis, semantic search enablement, and much more. Lionbridge AI also offers custom workflows to cater to your project’s specific needs.
Based in San Francisco, Scale is a provider of computer vision and NLP data annotation services. Through a combination of human work and Scale’s platform, the company provides the following text annotation services: OCR transcription, text categorization, and comparison.
With a huge source of crowdworkers from various countries, Appen is a provider of numerous forms of AI training data. In regards to text annotation services, Appen provides sentiment annotation, intent annotation, named entity annotation, and more.
Based in Poland, Tagtog is a text annotation tool that can be used to annotate text both automatically or manually. Tagtog supports native PDF annotation and includes pre-trained NER models for automatic text annotation. On top of the Tagtog tool, the company also has a network of expert workers from various fields that can annotate specialized texts.
One problem many AI researchers and developers face is getting access to AI training data for highly specialized fields. The team at KConnect seeks to help annotators quickly and efficiently classify and annotate medical data. Specifically, KConnect provides semantic annotation, text analysis, and semantic search services for medical information.
Based in the United States and Germany, Clickworker is a crowdsourcing company that has a huge workforce able to perform a variety of tasks. Some of their services regarding text annotation are sentiment analysis, and categorization.
ParallelDots is a provider of numerous APIs which can be used for various types of text annotation. Some of their solutions include sentiment analysis, emotion analysis, keyword extractors, and named entity recognition.
The LightTag text annotation tool is a platform for annotators and companies to label their text data in house. While the starter package is free, each package level rises in cost and has a monthly limited amount of annotations, starting from 1000 annotations a month.
A relatively new startup company based in Italy, Dandelion API provides a variety of automatic text annotation tools. Their tools can be used for entity extraction, sentiment analysis, and text and content classification.
With an in-house API for data annotation and thousands of partnered outsourcing companies, Dataturks provides various image annotation and text annotation services. Some of their text labeling services include text classification, named entity recognition, and part-of-speech labeling.
Featuring data engineering with SQL, Microsoft’s Build Conference and some cutting-edge Image Segmentation research.
Welcome to My Week in AI! Each week this blog will have the following parts:
An update on my work in AI
An overview of an exciting and emerging piece of AI research
Progress Report
Refreshing SQL skills
This week I decided to focus on renewing my data engineering skills, as this is my least refined and practiced skillset. I started with the basics – SQL and databases, since I have not touched on these areas in almost two years. I started the ‘Master SQL for Data Science’ learning pathway on LinkedIn Learning, which consists of 7 courses focusing on SQL, NoSQL and Presto. I still maintain that SQL is the most intuitive programming language I have learned so there was not much in the way of new topics for me in these courses. However, they were all well taught and comprehensive, and so overall a useful refresh for me of SQL.
Attending Microsoft Build Conference
Another big portion of my week was spent attending talks at Microsoft’s Build Conference. One of the silver linings of events having to move online and be remote due to the pandemic has been that they have been opened up to wider audiences. Whilst I was very interested in this event, it is one that I would not have been otherwise able to attend since it was based in Seattle. The conference offered a multitude of talks ranging from cloud infrastructure and DevOps to AI and sustainability. I mainly attended the AI/ML and sustainability related talks, and had two key takeaways:
There is an industry-wide push for transparency, ethics and accountability in AI.
Azure is a hugely powerful cloud platform.
In terms of ethical AI, two talks stood out to me. The first was titled: “Responsible ML: Protect Privacy and Confidentiality with ML” by Sarah Bird, and the second: “How to Explain Text Models with InterpretML — Deep Dive” by Minsoo Thigpen
In the first, Bird spoke about the privacy and security related AI initiatives that are being developed by Microsoft, including the WhiteNoise project focusing on differential privacy. This is an open source project that you can plug in to your machine learning pipeline, allowing you to add statistical noise to data to share sensitive datasets in a responsible manner — the key facet of differential privacy. Two applications suggested were anonymizing individuals’ incomes when working with census data and anonymizing medical diagnosis data. Overall this approach keeps the distribution of the data similar to the original distribution such that model performance is minimally (if at all) compromised, whilst protecting individuals’ identities.
In the second, Thigpen discussed InterpretML, another open source project by Microsoft that brings interpretability to NLP models. It currently works with BERT, RNNs and Scikit-Learn models and has three explainers implemented (I won’t go into the details here): Classical Text Explainer, Unified Information Explainer and Introspective Rationale Explainer. One of the applications presented was for hiring managers who use NLP to classify job applicants’ resumes. This package would give those managers insight into which key words in the resume led to a particular classification. The cool thing about this is that usually Deep Learning models are blackbox and interpreting them is very difficult, but this project allows you to do that to some extent.
Artificial Intelligence Jobs
Another takeaway I have from the conference regards the proliferation, power and ease of use of Azure ML. My dad, who worked at Microsoft in the 80’s and 90’s and who keeps up to date on all things Microsoft, has told me several times that Azure is the cloud computing environment used by the majority of large companies and that AWS is the cloud computing environment used by smaller companies and startups. It’s true: during the Build conference I found out that 95% of the Fortune 500 were using Azure — so in my opinion it’s definitely worth becoming familiar with both AWS and Azure.
Emerging Research
Promising Image Segmentation Method
The research I’m presenting this week focuses on Image Segmentation, which is a Computer Vision task that consists of identifying objects within an image. In their paper ‘Leveraging Pretrained Image Classifiers for Language-Based Segmentation’, Golub, El-Kishky and Martín-Martín presented a novel way of segmenting an image with classes that were unseen during training¹. This is exciting because usually for such tasks you need a lot of training data that covers all potential classes seen at test time, which is expensive and time-consuming. Typically, there are two main groups of methods that aim to overcome this problem: weakly supervised methods and few-shot semantic segmentation. However, both require some human generated labels at test time.
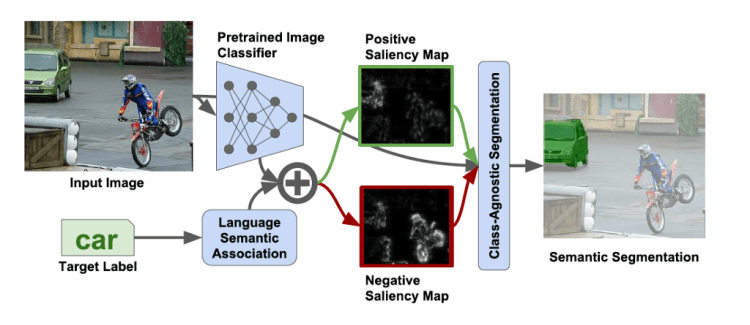
The new method proposed by Golub et al. instead utilizes Computer Vision and NLP approaches, and critically does not need any human generated labels during testing. Figure 1 shows diagrammatically their approach.
Golub et al. Image Segmentation Methodology¹
The input image is passed through a pretrained image classifier (in their case they used Imagenet-1k VGG-19) whilst the label is passed through a language semantic association model (in their case they explored WordNet and Word2vec, eventually landing on WordNet). The outputs of the classifier and language model are combined to produce positive and negative saliency maps for the image, and these two maps are fed into a semantic segmentation model with attention. This model outputs the probability that each pixel belongs to each class label. In experiments, this approach achieved 3.2% higher accuracy than the previous state of the art 5-shot approach.
I think the most fascinating conclusion of this work is that it can generalize to classes unseen during training. This means that you can achieve good results with less training data than required for other image segmentation techniques, and this approach may work well in the real world where you are likely to come across previously unseen objects. As someone with a keen interest in NLP I was intrigued by the way the researchers utilized WordNet in what is ostensibly a computer vision task. Transfer learning is another interest of mine, so the usage of the ImageNet classifier here also piqued my curiosity.
All in all, a productive first week after graduation! Stay tuned next week for more data engineering and a continuing look into research. Thanks for reading and I appreciate any comments/feedback/questions.
References
[1] D. Golub, A. El-Kishky and R. Martín-Martín, “Leveraging Pretrained Image Classifiers for Language-Based Segmentation,” 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 2020, pp. 1999–2008, doi: 10.1109/WACV45572.2020.9093453.
While machine learning is impacting organizations around the world, some are driving forward the real-world applications of innovative AI. Check out these interesting companies to watch for exciting new progress this year.
Calculus is the key to fully understanding how neural networks function. Go beyond a surface understanding of this mathematics discipline with these free course materials from MIT.
Speed up your Numpy and Pandas with NumExpr Package; A Layman’s Guide to Data Science. Part 3: Data Science Workflow; Getting Started with TensorFlow 2; Feature Engineering in SQL and Python: A Hybrid Approach; Deploy Machine Learning Pipeline on AWS Fargate