365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
Data science is helping with one of the world’s most pressing issues. Read about an approach and specific steps being taken by data scientists to quickly reduce pollution and greenhouse gas emissions.
Missing values in a dataset impact the analysis, training and predictions significantly based on a few different factors. Let’s dig deep in and see.
What are the missing values?
In statistics, missing data or missing values occur when no data value is stored for the variable in an observation or instance. when considering a single instance it could be a corrupted or unrecorded data point but when considering the whole data set, it could have a pattern or in the other hand completely random.
For many reasons, it is important to categorize the pattern of missing values.
Univariate or multivariate: only one attribute has missing values or more than one attribute has missing values.
Univariate or multivariate Missing value pattern
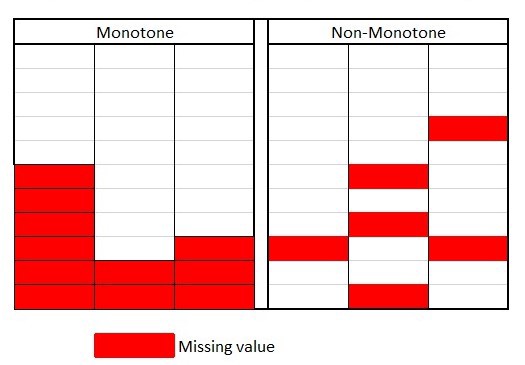
2. Monotone and non-monotone: if a variable has completely missed after a certain instance and not recorded at all, then it is monotone.
Monotone and Non-Monotone missing value pattern
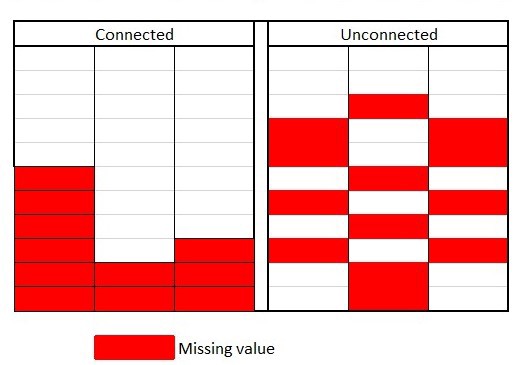
3. Connected and unconnected: if any observed data point can be reached from any other observed data point by moving in horizontal or vertical paths.
Connected and unconnected Missing value pattern
4. Planned and Random
Planned and Random Missing value pattern
The above categories can be determined by observation but when the dataset gets bigger and moves from kilobytes to a few hundred megabytes, it becomes impossible to visualize and come to and conclusion.
Determine the randomness of missing data
There three main stages of missing values, Missing at Random(MAR), Missing Completely at Random(MCAR), Missing Not at Random(MNAR). When it comes to determining these, in 1988, the Journal of the American Statistical Association has published a method called “Little’s test of missing completely at random”. Which is useful for testing the assumption of missing completely at random for multivariate, partially observed quantitative data.
Missing values have to be handled based on their distributions to achieve reasonable accuracy in the training model. To confirm the randomness of missing values, Little’s MCAR test should be performed. The potential bias due to missing data depends on the mechanism causing the data to be missing. The analytical methods applied to amend the missingness are tested using the chi-square test of MCAR for multivariate quantitative data. It tests whether there exists a significant difference between the means of different missing-value patterns.
Data Scientist Jobs
When handling missing values in Machine Learning, most of the time the preprocessing part address missing data, Usually if there are more than 20% of the data is missing in one attribute then it would be harder to fill or recover those values without affecting the training. The best solution would be to drop such kind of attributes and fill the rest of the attributes using a proper mechanism.
Here are some examples of using Little’s MCAR method:
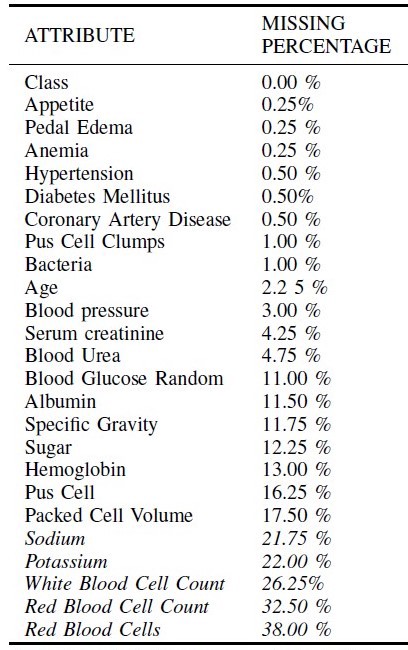
CKD dataset from UCI repository When considering the bellow dataset the last 4 attributes have to be taken out because of the high missing value proportion.
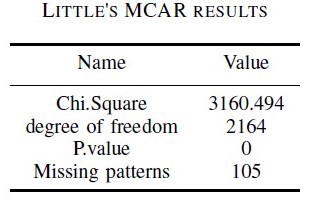
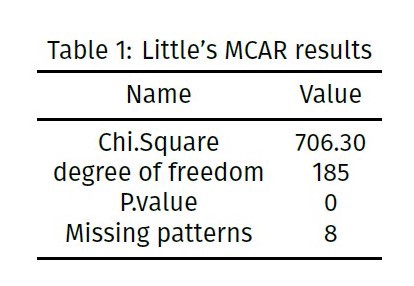
The littles MCAR test results,
When considering the above table it clearly shows the P.value of the test is zero, since it’s less than 0.05, it says that the missing data is Missing Completely at Random(MCAR).
Delete all instances with at least a missing value: If you do this method then, the size of the dataset should be large enough to represent the population without those instances.
Recover redoing the experiment or contacting the subject:This is one of the high-cost methods to recover the values, redoing an experiment takes time and cost money, moreover if it’s a public opinion kind of dataset, then acts like GDPR restrict future uses to contact the subject in some cases.
Domain Experts Guessing:By consulting the domain experts it is possible to guess the missing values with their experience but this method is a hectic and highly cost method due to the high hourly rates of experts.
Fill with mean:This is one of the easiest and most primary methods of imputing missing values, by filling each missing value with the average of the attribute. This is not always good to use because it reduces the variability of the data but in some cases makes sense.
Fill with median:Similar to the above method the problem is it reduces the variability of the data. Moreover, if the missing values are distributed then it could increase the noise of the data as well.
Using Machine Learning algorithms:There are two different ways of using ML for imputation, first themultiple-regressionanalysis, by creating a regression equation using the rest of the data it is possible to predict missing values. This method needs more complete instances to train the model. Finally, the most common and popular method is theMultiple Imputation.where there are multiple missing values based on the correlations for the missing data and then averages the simulated datasets by incorporating random errors in your predictions
Here is one of my favourite missing value imputer, KNNImputer. The KNNImputer class provides imputation for filling in missing values using the k-Nearest Neighbors approach. Usually, the euclidean distance metric that supports missing values is used to find the nearest neighbours but depending on the dataset you can use preferred distancing method better for the dataset as you want, in advance cases, you can use a weighted average for each instance and then consider the centroid of the included points. The Missing values will be imputed from the attribute average of the nearest predefined number of neighbours. One of the key problems is finding the missing values for outliers, so even though you don’t have all the points required nearby, you can take the average or weighted average of points nearby to that specific instance. for that, you have to define the maximum distance from 2 instances to be considered.
The main benefit of the above method is, it doesn’t have to train the dataset and predict where it uses the distances and Spatiality of the data points.
Easy Natural Language Processing tutorial using NLTK package in Python
Natural Language Processing (NLP) is an area of computer science and artificial intelligence concerned with interactions between computer and human(natural) language.
Well, wondering what is NLTK? the Natural Language Toolkit, or more commonly NLTK, is a suite of libraries and programs for symbolic and statistical natural language processing (NLP) for English written in the Python programming language. It was developed by Steven Bird and Edward Loper in the Department of Computer and Information Science at the University of Pennsylvania.
The basic task in NLP are:
1.convert text to lower case 2. word tokenize 3. sent tokenize 4. stop words removal 5. lemma 6. stem 7. get word frequency 8. pos tags 9. NER
It is necessary to convert the text to lower case as it is case sensitive.
text = “This is a Demo Text for NLP using NLTK. Full form of NLTK is Natural Language Toolkit” lower_text = text.lower() print (lower_text)
[OUTPUT]: this is a demo text for nlp using nltk. full form of nltk is natural language toolkit
Data Scientist Jobs
3. word tokenize
Tokenize sentences to get the tokens of the text i.e breaking the sentences into words.
text = “This is a Demo Text for NLP using NLTK. Full form of NLTK is Natural Language Toolkit” word_tokens = nltk.word_tokenize(text) print (word_tokens)
Tokenize sentences if the there are more than 1 sentence i.e breaking the sentences to list of sentence.
text = “This is a Demo Text for NLP using NLTK. Full form of NLTK is Natural Language Toolkit” sent_token = nltk.sent_tokenize(text) print (sent_token)
[OUTPUT]: ['This is a Demo Text for NLP using NLTK.', 'Full form of NLTK is Natural Language Toolkit']
5. stop words removal
Remove irrelevant words using nltk stop words like is,the,a etc from the sentences as they don’t carry any information.
import nltk from nltk.corpus import stopwords stopword = stopwords.words(‘english’)
text = “This is a Demo Text for NLP using NLTK. Full form of NLTK is Natural Language Toolkit” word_tokens = nltk.word_tokenize(text) removing_stopwords = [word for word in word_tokens if word not in stopword] print (removing_stopwords)
text = “the dogs are barking outside. Are the cats in the garden?” word_tokens = nltk.word_tokenize(text) lemmatized_word = [wordnet_lemmatizer.lemmatize(word) for word in word_tokens] print (lemmatized_word)
text = “This is a Demo Text for NLP using NLTK. Full form of NLTK is Natural Language Toolkit” word_tokens = nltk.word_tokenize(text) stemmed_word = [snowball_stemmer.stem(word) for word in word_tokens] print (stemmed_word)
counting the word occurrence using FreqDist library
import nltk from nltk import FreqDist text = “This is a Demo Text for NLP using NLTK. Full form of NLTK is Natural Language Toolkit” word = nltk.word_tokenize(text.lower()) freq = FreqDist(word) print (freq.most_common(5))
NER(Named Entity Recognition) is the process of getting the entity names
import nltk text = “who is Barrack Obama” word = nltk.word_tokenize(text) pos_tag = nltk.pos_tag(word) chunk = nltk.ne_chunk(pos_tag) NE = [ “ “.join(w for w, t in ele) for ele in chunk if isinstance(ele, nltk.Tree)] print (NE)
[OUTPUT]: ['Barrack Obama']
PS: Execute all those code and tada!!! you know the basics of NLP ?
5 Best Data Science online degree Programs from Universities you can join
Hello guys, I have been sharing some online degree programs you can take online from last a couple of weeks as more and more people are looking for online technical degree programs.
Earlier, I have shared Top 5 Computer Science degree you can earn online, and today, I will share the 5 best Data Science and Machine learning degrees you can earn online from the world’s reputed universities.
Data Science is the way or the process of extracting insights and useful information from your data to understand different things and turn that data into a story in the shape of graphs and a dashboard that anyone can understand and by using many different programming languages like Python and R. But imagine if you can earn an online degree in this topic, that’s what we are covering in this article.
The field of Data Science is one of the standard in-demand fields in today’s world, and some of the people called the future career or job since the world demands people who can obtain valuable insight from data to produce a better application or for a better understanding of the world and here comes the job for a data scientist.
In this article, we will see some of the online programs offered by world’s best universities that will give you an online degree in data science like a master’s degree without the need to go to college and spend more money or getting a visa if you are an international student wanting to study abroad.
If you are keen to start your career on Machine learning but you are looking for a more flexible and affordable option then you can also join a comprehensive Machine learning course like The Data Science Course 2020: Complete Data Science Bootcamp by 365 Careers. It’s one of the most popular and highly useful courses to learn Data Science and Machine learning skills on Udemy online.
This master’s degree given by the University of Illinois will provide you the data science experiences that are needed to get a position in the job market.
If you joined in this program, you would study some other topics that are related to data science such as machine learning, data visualization, data mining, and cloud computing.
The program costs you around $21,400, and you need to pay just for every course you take, which are 8 courses in the whole degree with an effort about 10–12 hours per week for the next 12 to 36 months.
This master’s degree program teaches you how to use data to extract insights and useful information, enhance outcomes, and accomplish ambitious goals. It is designed for the data scientist to shows them how to apply data science skills through hands-on projects.
This master’s degree equips the students to real-world data science skills that are essential to be applied in the market.
Through this master’s degree, you will work beside and on projects with the other students from all around the globe. The cost of the degree would be $31,688 for students who live in the Michigan State and $42,262 for the out of Michigan State students.
There are no prerequisites, which means that anyone can be joining this master’s degree in the data science program offered by the university of colorado.
Still, you need to pass the exam created by this university to be officially enrolled in this program.
You will be training on real-world projects using real-world datasets on the cloud environment and Jupiter notebook, so to qualify you for a career in data science and gets a job in this field.
It is totally online and may take you two years to complete it and get certified.
This course won’t teach you only data science. Still, it will also boost your career as a professional data scientist in the industry of machine learning, deep learning, computational statistic, and propel you to become a data scientist.
By practicing on real projects, you will see your portfolio, and you can showcase your skills in machine learning, deep learning, data science, and your analytics skills to your employees.
The program costs £28,000 and can take you up to 24 months to complete it and get your certification.
This master’s degree offered by texas university walk you first through the principal of what data science is, then you will learn other topics that involve in this field like machine learning, data visualization, data analysis, data mining, simulation, and much more.
This master’s degree costs around $10,000 and can take you up to 1.5 to 3 years, depending on your learning time and efforts. It contained 10 courses, and it needs to have either TOEFL or IELTS exam to enroll in this program, your degree will be considered exactly like that of an on-campus graduate.
That’s all about the best Data Science and Machine learning degrees you can earn online from reputed universities all over the world. Thanks to Coursera and edX Team, now, getting a master’s degree in data science has become more comfortable with these online programs without the cost of traveling or visas or renting a room with your colleagues, and all you have to do is picking up one course and start the learning unit you get certified.
Other useful Data Science and Machine Learning resources
Thanks for reading this article so far. If you find these Data Science and Machine learning online degree courses from Coursera and edX useful, then please share it with your friends and colleagues. If you have any questions or feedback, then please drop a note.
P. S. — If you are keen to start your career on Data Science and Machine learning but you can’t afford these online degree courses then don’t disappoint, you can still get these useful skills by joining a solid course like The Data Science Course 2020: Complete Data Science Bootcamp by 365 Careers.
Learn about the latest version of TensorFlow with this hands-on walk-through of implementing a classification problem with deep learning, how to plot it, and how to improve its results.
PyTorch Lightning, a very light-weight structure for PyTorch, recently released version 0.8.1, a major milestone. With incredible user adoption and growth, they are continuing to build tools to easily do AI research.
Chatbot Conference is the premier conference on Bots, AI, Voice and we are now sharing all of our videos on Youtube for Free!
Our events feature the top industry experts from companies like Google, Facebook, Amazon, Walmart, Oracle, Siruis, Rasa, 1–800 Flowers, Dashbot and many more!
The results show that despite the deluge of Big Data, large majority still works in Gigabyte or Megabyte-size datasets. Data Scientists work with the largest-size datasets, followed by Data Engineers, Data Analysts, and Business Analysts. Read more for details.


















{kind=link}
{kind=link}
{kind=link}