365 Data Science is an online educational career website that offers the incredible opportunity to find your way into the data science world no matter your previous knowledge and experience.
So, are you confused by the title? Of course I got an interview for amazon ML Engineer position and I have failed because of my mistakes. I want to share my experience with you, so that you don’t make mistakes I have made.
I have given interview to amazon for ML Engineer position in January 2021. I am sharing my experience from how I got the interview and how not to bomb it.
So, in November 2020, amazon hosted a hackathon on Hacker-Earth website to hire ML Engineers in India. Naturally as a data science learner I have participated in the Hackathon.
In round 1 of the hackathon we were asked to built a classifier for an ecommerce website to know whether to target a person or not based on the historical data available for the ecommerce website. We were also told to make a presentation for the same.
Big Data Jobs
Data Cleaning
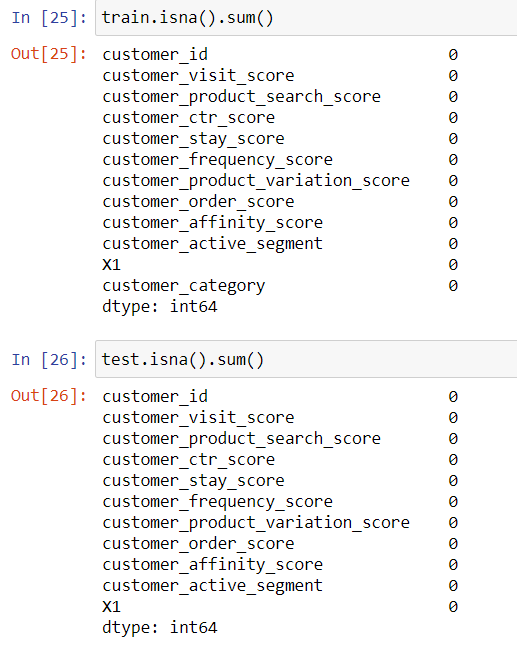
I have loaded the train and test data and checked for null values.
I have filled the null values in columns having object data type by mode values and numeric data types by their median values.
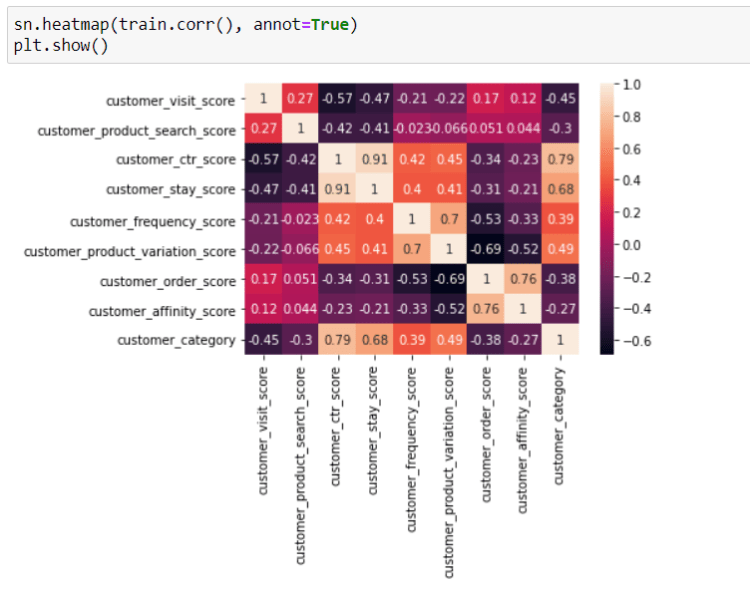
Later on I have to eliminate the numerical features which were highly correlated with each other, so that the model will have lower the variance of the weights. I have retained features having correlation coefficients between -0.5 and 0.5.
I found that customer_affinity_score column has outliers. Removing outliers by keeping data points between IQR range was resulting in removing some of the unique categorical data points and was giving problems while doing One Hot Encoding. Hence I have retained the data points with outliers having customer_affinity_score less than 125. I have done One Hot Encoding for the object dtype columns to convert them to numeric data type.
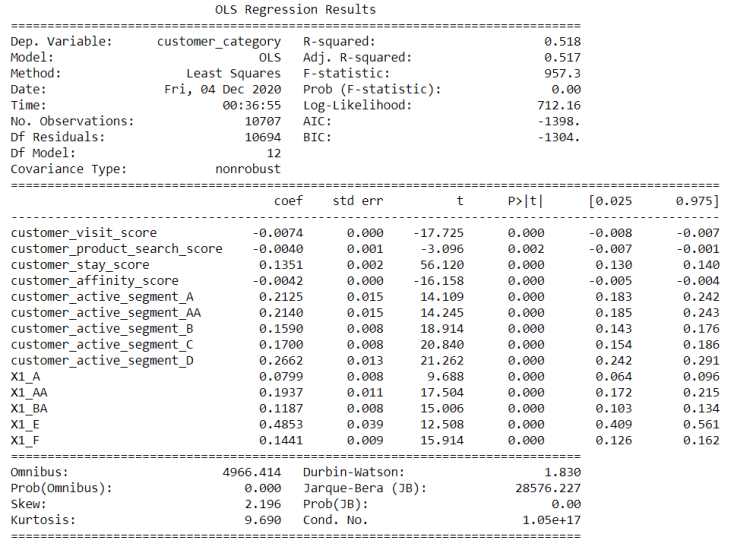
At this point data was cleaned and I have to decide which features to keep for further analysis. I have created an OLS model to know the p values of the columns to find out which columns are important. Since, all p values were less than 0.05 that is in the range 0f 95% confidence interval, I have retained all the columns.
Model creation
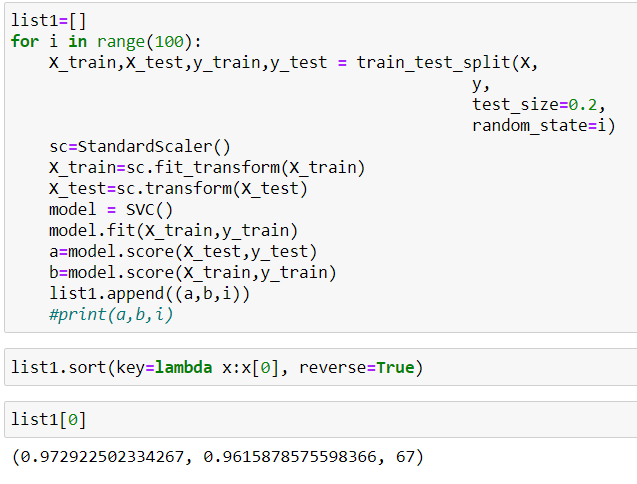
Now it was the time to create the model. I have tried Random Forest, XG Boost and SVM models for this particular problem. Since, random state at the time of splitting the data gives different train and test data, I experimented with it. I have looped the data from 0 to 99 random state and calculated the score for each model with different split by random state. I chose the model with highest score for the evaluation of each SVM classifier, Random Forest Classifier and XG Boost Classifier. I chose SVM Classifier as it was giving me a generalized model compared to Random Forest Classifier and XG Boost Classifier.
I found that random state 67 giving best score on test data set. Also the model is generalized model as it is giving more score on validation dataset than the train dataset.
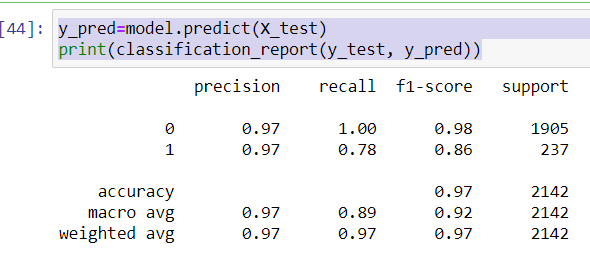
Since, the evaluation metric for this hackathon was precision and I was getting 97% precision on validation data, I have moved forward with this model.
Finally I have made prediction on test data and saved it as final submission.
Prediction
So, I have prepared the notebook and presentation for the hackathon and submitted it for evaluation. I have got 93.7% precision on their actual test data.
Round 1 was cleared, round 2 was a coding exercise, I have cleared that as well. Now, I was so happy after hearing that I have cleared the initial rounds, when the recruiter asked, if is it fine to schedule interview next day? I immediately told yes and that was my biggest mistake.
It was the interview of world’s most customer centric company which promises to deliver the customer anything they wanted on their online platform and I have not thought of how am I going to prepare for the interview in one day.
The result was, I failed to crack the amazon interview. I learnt from my this mistake that impatience is the enemy of success. I wanted to share my experience with you all so that you don’t repeat the mistake I have done.
After all patience is bitter but the fruit is sweet!
Software developers and cyber security experts have long fought the good fight against vulnerabilities in code to defend against hackers. A new, subtle approach to maliciously targeting machine learning models has been a recent hot topic in research, but its statistical nature makes it difficult to find and patch these so-called adversarial attacks. Such threats in the real-world are becoming imminent as the adoption of machine learning spreads, and a systematic defense must be implemented.
The rise in machine learning project implementation is coming, as is the the number of failures, due to several implementation and maintenance challenges. The first step of closing this gap lies in understanding the reasons for the failure.
Although corporate spending on artificial intelligencetopped $50 billion last year, just 11% of companies that enhanced their workflows with AIhave already seen a significant return on their investments. In this article, we’ll investigate business, technological, and ethical issues haunting AI projects — and provide several tips to seamlessly integrate Artificial Intelligence into your company’s Digital Transformation strategy.
A rundown of AI implementation challenges
Hitting Technology Roadblocks
Although AI has been around since the mid-50s, voice assistants, face swap apps, and robot dogs only became mainstream a couple of years ago. As of now, neither businesses nor their technology partners have a tried-and-true formula for creating and implementing artificial intelligence solutions. Some of the common AI pitfalls include:
Poor architecture choices
Making accurate predictions is not the only thing you should expect from an AI system. In multi-tenant applications (think AIaaS solutions serving thousands of users), performance, scalability, and effortless management are equally important. So you cannot expect your vendor to just write a Flask service, wrap it in a Docker container, and deploy your ML model. The approach might work for a certain number of users; once the system hits its limits, you’ll get an elephantine application that is also expensive to operate.
Big Data Jobs
SNIPPETS
Inaccurate or insufficient training data
AI-based systems are only as good as the data they’ve been fed on. In some cases, companies struggle to provide quality data (and a substantial volume thereof!) to train AI algorithms. The situation is not uncommon in healthcare, where patient data like X-ray images and CT scans is hard to obtain due to privacy reasons. To increase the amount of training data and build a better model, it is sometimes necessary to manually label data using annotation tools like Supervise.ly. According to Gartner, data-related AI problems is the #1 reason why 85% of artificial intelligence projects will deliver erroneous results through 2022.
Lack of AI explainability
Explainable artificial intelligence (XAI) is a concept that revolves around providing enough data to clarify how AI systems come to their decisions. Powered by white-box algorithms, XAI-compliant solutions deliver results that can be interpreted by both developers and subject matter experts. Ensuring AI explainability is critical across a variety of industries where smart systems are used. For example, a person operating injection molding machines at a plastic factory should be able to comprehend why the novel predictive maintenance system recommends running the machine in a certain way — and reverse bad decisions. Compared to black-box models like neural networks and complicated ensembles, however, white-box AI models may lack accuracy and predictive capacity, which somewhat undermines the whole notion of artificial intelligence.
To avoid these (and many others!) AI pitfalls, we recommend that you start your artificial intelligence project with a discovery phase and create a proof of concept
This would allow you to map the solution requirements against your business needs, eliminate technology barriers, and plan the system architecture with the anticipated number of users in mind. It is also important to select a technology partner who knows how to overcome the data-related challenges of artificial intelligence — for instance, by reusing existing algorithms or deliberately expanding the size of a training dataset.
Replicating lab results in real-life situations
An AI-based breast cancer scanning system created by Google Health and Imperial College London reportedly delivers fewer false-positive results than two certified radiologists. In 2017, Oxford and Google DeepMind scientists developed a deep neural network that reads people’s lips with 93% accuracy (compared to just 52% scored by humans). And now there’s evidence that machine learning models can accurately detect COVID-19 in asymptomatic patients based on a cellphone-recorded cough! When fueled by powerful hardware and a wealth of training data, AI algorithms can perform a wide range of tasks on a par with humans specialists — and even outmatch them.
The problem with AI is, most companies fail to replicate the results achieved by Google, Microsoft, and MIT — or the accuracy displayed by their own AI prototypes — outside the laboratory walls.
The solution to this daunting AI problem partially lies in tech giants’ willingness to share complete research findings and source code with fellow scientists and AI developers. On a company level, it is crucial to analyze how smart algorithms will perform when faced with unfamiliar or poorly structured data and devise mechanisms to support the functioning of AI-powered applications under heavy load.
Scaling Artificial Intelligence
According to Gartner, only 53% of AI projects make it from prototypes to production, which means most companies lack the technical talent, skills, and tools to implement smart systems at scale. Continuous knowledge transfer might be a viable solution to this problem. While most companies currently rely on 3rd-party vendors to build smart systems and put them to work, forward-thinking CIOs and IT leaders must ensure their pilot projects help transfer knowledge from external DevOps, MLOps, and DataOps specialists. This way, enterprises could upscale their in-house capabilities before moving AI prototypes into production.
Overestimating AI’s power
Back in October, MIT Sloan Management Review and Boston Consulting Group unveiled a report that sheds some light on why some companies benefit from AI (while others don’t). DHL, a postal and logistics company that delivers 1.5 billion parcels a year, is among the AI winners. The company uses a computer vision system to determine whether shipping pallets can be stacked together and optimize space in cargo planes. Gina Chung, VP of innovation at DHL, says the AI solution performed poorly in its early days. Once the system started learning from human experts who had years of experience detecting non-stackable pallets, the results improved dramatically.
If complete automation and reduction in your company’s headcount lie at the heart of your AI implementation strategy, you are likely to fail.
For one thing, algorithms need human knowledge to eventually make accurate predictions. And for another, your employees will feel more enthusiastic about teaching algorithms if you make it clear smart machines won’t replace the human workforce in the foreseeable future.
Dealing with AI ethical issues
Greater adoption of smart applications comes along with several AI ethical issues, including:
Bias in algorithmic decision making, which stems from flawed training data prepared by human engineers and bears the mark of social and historical inequities
Moral implications, which mainly revolve around companies’ intent to replace human workers with highly productive, always-on robots
Some AI solutions do inherit racial and gender prejudice from their creators. A facial recognition system deployed by US law enforcement agencies, for instance, is more likely to identify a non-white person as a criminal. However, your company can solve most of these problems by creating balanced training datasets that include images of people representing different ethnic, gender, and age groups. In fact, artificial intelligence can help us eliminate racial, gender, age, and sexual orientation bias in the long run. For example, AI-powered HR management software can scan more resumes than human specialists and identify potential candidates based solely on their education and working experience. And while some industries indeed register persistent changes in their workforce size due to artificial intelligence implementation, it turns out AI will actually create 3% more jobs than it’s going to kill!
How to overcome AI implementation challenges: take-home message
Address an AI vendor with the relevant portfolio and expertise
Work with a skilled business analyst to determine which of your processes and IT systems could benefit from AI
Consider how ethical issues might prevent you from using AI to the fullest
Create a proof of concept to test the solution feasibility and work around technology-related AI pitfalls
Devise a detailed AI project implementation map covering solution development, integration, and scaling, as well as employee onboarding
Together with your vendor, start building your system while ensuring continuous knowledge sharing
Do not raise your hopes high: it takes time, patience, and lots of data to build AI solutions capable of enhancing or taking over critical tasks
Appoint subject matter experts to fine-tune AI algorithms
Educate your employees about the importance of data-driven decision making and optimization opportunities offered by artificial intelligence
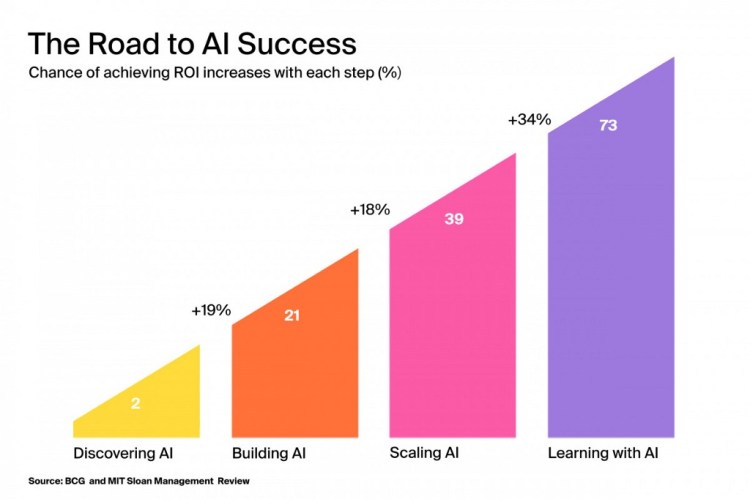
Last but not least, continue experimenting with AI — even if your pilot project does not deliver on its promise! 73% of companies that overhaul their processes based on the lessons learned from failures eventually see a sizable ROI on their artificial intelligence investments.
If you need help building, scaling, or tuning an AI solution, feel free to contact the ITRex team, and we’ll connect you with the right expert!
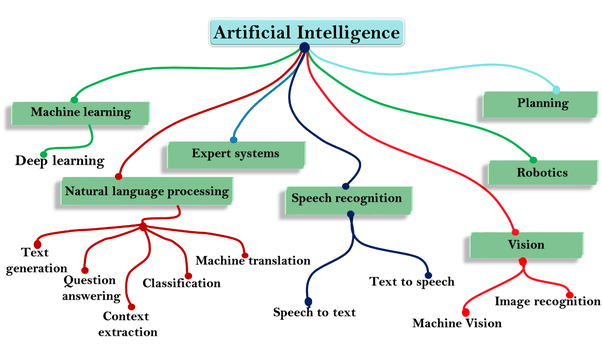
Most people often get confused with these terms since they are all interrelated. However, let me give my best shot and explain it with the simplest definition.
Picture this, artificial intelligence is the father of machine learning, and natural language processing, whereas deep learning is a subfield of machine learning.
AI Tree
Artificial Intelligence (AI)
Well first of all the term was meant to describe the goal that machines will be able to have humans-like intelligence in the future ( yeah they don’t have so far I know). A lot of money was invested in reaching this goal but we could not achieve our goal. Later we made a new type of AI ( say weak AI or the applied AI that we are having today) which focuses on making machines or systems that LOOK or SEEM to be intelligent ( but are not intelligent). Some of you may be confused. Well so basically there are two types of AI: weak AI and strong AI ( also can say applied AI and general AI ). So far the so-called AI everywhere you see in machines or listen about is weak AI. Strong AI systems will have their consciousness, sentience, etc ( say having brains just like that of humans).
Big Data Jobs
SNIPPETS
Some people also consider that weak AI is not the true AI and companies for sake of better promotions of their products and better market brought the word weak AI ( that is not intelligence according to so some guys I mean and it used as AI by companies just because the word AI sounds very fancy ). So AI is just about creating intelligent machines ( let it get achieved anyhow) I mean make machines or systems that seem to be intelligent like us ( or are like us).
Machine Learning (ML)
Machine learning would not be a subset of AI completely had we achieved strong AI ( because we have only weak AI in real-world ML is a subset of AI … actually ML is subset of weak AI ). Let me clear this. What exactly makes machine learning different from normal learning. Machine learning is a better method of training machines than the old traditional methods ( i know even ML is quite old now but I’m comparing it to methods even before its origin) . Let me give an example. You have to make software for bitcoin trading. You know the exact algorithm that can give the desired output, so you make that algorithm and it inputs all the required values and gives an output. This is normal learning.
Now the reality is you know factors that can influence bitcoin movements to say indicators like RSI, CSI, MACD ( many indicators); graphical history ( comparing historical movements), buy and sell walls, and a lot more. You can’t figure out how to make a proper mathematical operation for this thing ( actually you yourself are not sure about it, you just know the PARAMETERS that influence its movement). Well so you make a program that randomly combines all these ( with different input values ) and keeps working hard and tries to make a mathematical formula itself ( a directional hit and try approach). You keep giving it more and more data of bitcoin ( also other cryptocurrencies you can give here in this case) so that it can keep trying things and figure out itself a formula that will give good accuracy ( you yourself may not understand what the hell this program is doing because it becomes so complicated, all you do is keep giving it data and just want a good accuracy ). This is machine learning say a machine that doesn’t learn because we keep updating its algorithm … it learns from its experience ( experience for machines is data input vs result accuracy) .. it keeps modifying itself to improve the accuracy of the result. Sometimes you are not even sure about exact parameters and add all parameters that could be possible and leave all that at your machine to figure out things.
Now you can see that machine learning is a completely different thing from AI but in the real-world, we use machine learning as an approach to achieve AI. Let me explain. Suppose we make machines that are exactly like us in all aspects ( strong AI). you show a laptop to the machine and whenever you show another dog it will most probably figure out that it’s a laptop. But what real machines of today need is the processing of millions of pics of laptops to reach a good accuracy where they can figure out the laptops. What I mean is we simply use machine learning to make these weak AI machines ( i mean had we built strong AI we would not use these kinds of approaches… ). Maybe the growing nanotech and other developments help us reach strong AI but till then we have weak AI and ML is clearly a subset of it.
Again I remind you ML is a subset of AI. let me give you a better example. You have seen automatic cars which companies claim to be AI-based cars. There are two types of cars: based on set rules and based on ML. Both these types of cars companies call AI-based cars ( because for a normal guy they seem to be intelligent and driving just like we humans ). In cars with set rules, we have to change to go to keep making changes which in the case of ML-based they keep improving they’re also with the experience they get. So AI can be achieved by many methods one of which is ML. Because most of AI nowadays achieve AI using ML you will find people interchanging these words often ( and that would hardly make a difference).
Natural Language Processing (NLP)
This is a subset of AI that uses ML algorithms for processing our natural languages like Hindi, English, etc ( not computer languages like C, JAVA etc) . What I mean is whenever you say a sentence figuring out its meaning ( same word can have many meanings ), grammar, subject or object of the sentence, etc is achieved via NLP. Different languages have different grammar and differ a lot in many aspects. NLP is also used for translation purposes from one language to another.
Deep Learning
This is a subset of ML inspired by the human brain ( if I speak in simple terms). We tried to understand the biological working of our brain and tried to figure out things leading to deep learning. We make models that are highly complicated having several small blocks where even slight changing of any block can result in the altering of the result. Deep Learning is what you find in the background of most ML systems ( and also indirectly most AI systems). Deep learning is the name we use for “stacked neural networks”; that is, networks composed of several layers. If you know well about neural networks then raise another query regarding Deep Learning and I will assist you there ( invite me there).
Extracting immediate predictions from machine learning algorithms on the spot based on brand-new data can offer a next level of interaction and potential value to its consumers. The infrastructure and tech stack required to implement such real-time systems is also next level, and many organizations — especially in the US — seem to be resisting. But, what even is real-time ML, and how can it deliver a better experience?