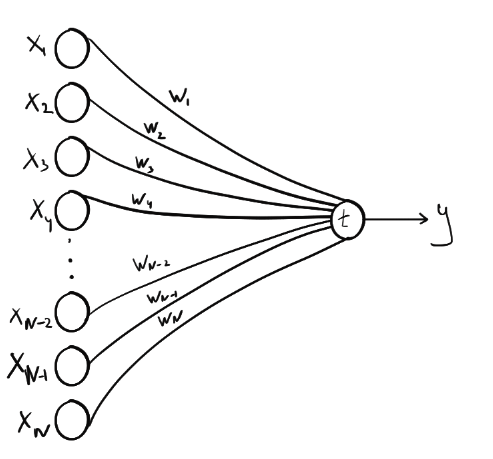
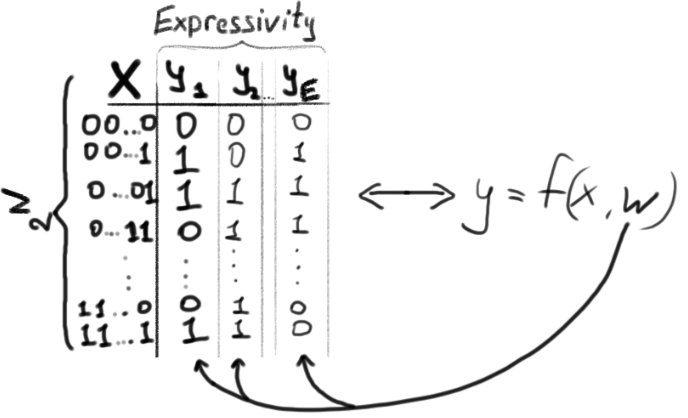
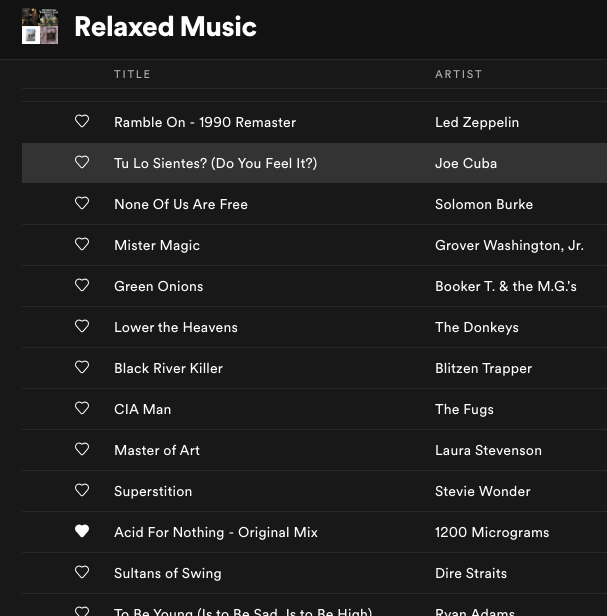
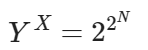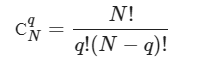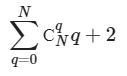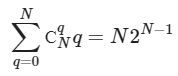In the past, machine learning against relevant data required some heavy lifting. Most of the machine learning for something like “sentiment analytics” against social media tweets and posts required a new way of thinking about data. Traditional rows and columns in a relational database can store the text of a message but do not do so well with a thumbs up or thumbs down icon… or an emoji or a meme.

As a human, we can easily look at the above images and we immediately know the sentiment for each image. For a computer, it’s not so easy. Suppose we are trying to learn how our products are perceived on social media. To start the process we pay for a massive dump of millions upon millions of relevant social media posts. Now we have to sort through all the data, match our specific products and we find there is a lot of icons and images. We have to store the data somewhere and then we have to process the images with machine learning to make sense of them. Next, we have to store the meaning of each image in a social media post back in a database of some sort to report how many of our customers feel a particular way about our products.

Traditional approaches to this problem utilized technologies like Hadoop and Spark. These technologies require complex infrastructure and intricate machine learning programs to deduce the meaning and provide the answer. The infrastructure investment is also significant both in cost and time. The specialized skill sets required are also not easy to find. And yet, even with the huge investment of time and capital, the payout in understanding may be worth the effort.
Hadoop’s initial release date was April 1, 2006, and it offered a new way of managing a problem with large amounts of unstructured or semi-structured data that didn’t really fit in the traditional relational database. It gave us a way of moving what at been previously thought impossible to actually possible, and gave us a new term: “Big Data”
Eight years later, in May of 2014, the initial release of Apache Spark made great advancements in speed and simplicity over the initial Hadoop Map Reduce. Machine learning with Spark MLlib and Spark ML offered the complete solution. It was possible with Hadoop and Spark ML to take any type of data, process it, and make assessments and predictions with machine learning.

A great deal has changed since Spark made its debut. Now we have the option of using the cloud to handle the infrastructure and scale-out and up when we have a big job and then scale back down when we are done. The benefit is zero-configuration, no upfront investment in hardware, and we only pay for what we use.
A second great leap forward took place in the advent of machine learning frameworks like Google’s TensorFlow. Not only is the infrastructure hosted as a service but now the machine learning platform itself is offered as a service.
The payoff is immense. The new cloud machine learning paradigm offers a low-cost simple solution. Instead of heavy upfront investments in hardware and months of development, the machine learning process is now done with a few skilled developers, a small amount of code, all running on a hosted platform.
Trending AI Articles:
1. Preparing for the Great Reset and The Future of Work in the New Normal

TensorFlow was developed by the Google Brain team for internal Google use. It was released under the Apache License 2.0 on November 9, 2015. In Jan 2019, Google announced TensorFlow 2.0. In May 2019, Google announced TensorFlow Graphics for deep learning in computer graphics. TensorFlow 2.0 became officially available in Sep 2019.
TensorFlow is an end-to-end open-source platform for machine learning. It has a comprehensive, flexible ecosystem of tools, libraries, and community resources that lets researchers push the state-of-the-art in ML and developers easily build and deploy ML-powered applications. Google claims, “Robust ML production anywhere. Easily train and deploy models in the cloud, on-prem, in the browser, or on-device no matter what language you use.”
What about the database? Much of today’s modern data is already stored as JSON documents, and with a simple process, most log entries and social media posts can be quickly converted to JSON. Once it is in JSON format, a modern document database is all you need to store the data. The proper queries against that data are all that is required to prepare it for machine learning. Even the icons can be base64 encoded and stored in the document if you like.
I decided to create my own machine learning project for a customer using Google TensorFlow and MongoDB Atlas. The customer (a convenience store operator) wanted to be able to predict the number of gallons sold based on gas price and temperature data. The question posed was “With only the input of the current temperature what would be the best price to maximize profit?” I was able to create the whole project without any prior knowledge of TensorFlow in about two weeks.
I put the finished project on GitHub here: https://github.com/brittonlaroche/realm-tensorflow If you are interested in learning AI / ML with TensorFlow and MongoDB Atlas and have zero experience I highly encourage you to take a look at the GitHub link, you could learn a lot in a short period of time.
Why MongoDB?

Reason Number 1: Flexible Data Model
MongoDB is one of the best databases for machine learning for several reasons. The first reason is that MongoDB stores JSON documents and has a flexible schema. Unlike a relational database where you have to define a schema and tables with column definitions, MongoDB allows you to load data directly without any upfront schema design. This means that you can load data from any new source and get to work immediately. Because of this basic flexibility, after I completed the work with the gas price data I then loaded in real estate data and performed machine learning on house prices without changing one single line of code.
Reason Number 2: Powerful Query Language
Once the data is loaded, MongoDB provides you with a powerful query language and secondary indexes to give you fast access to very specific values that you would want to use. You have the option to filter sort and aggregate the data, selecting and transforming the fields you need to use. This is a necessary step to prepare the data used for machine learning. This level of query sophistication not available in most NoSQL datastores.
Reason Number 3: Store and Retrieve Trained Models as JSON Documents
MongoDB is the perfect place to store, share, and retrieve the trained models. It is possible to not only store our models but keep a history of our models in the database allowing us to restore a trained model from a previous version if we chose to do so. You can create a simple trigger to store a copy of your model in a history collection. The history collection keeps a history of each of your trained models over time inside MongoDB. More importantly, sharing trained models reduce the time it takes to use those models for machine learning predictions. If I want to use an existing model for a prediction or for reinforcement learning I simply query MongoDB for the model and load it saving all the time it took to originally train the model.
Reason Number 4: MongoDB Atlas offers Database as a Service Across all Modern Cloud Providers
On June 28, 2016, MongoDB Atlas was released. Atlas is the simplest, most robust, and most cost-effective way to run MongoDB in the Cloud. Atlas is a database as a service that makes running MongoDB almost effortless, whether you run a single replica set, or a sharded cluster hosting hundreds of terabytes. As of October 2020, MongoDB Atlas was the first cloud database to enable customers to run applications simultaneously on all major cloud providers. Using multi-cloud clusters, customers can easily take advantage of the unique capabilities and reach of different cloud providers. This means customers can take advantage of the benefits of deploying applications across multiple cloud providers without the added operational complexity of managing data replication and migration across clouds. For instance, you can run your online store in Azure and have the data replicated to GCP in realtime for machine learning. Additionally, MongoDB Atlas allows you to create a free tier in any of the major cloud providers (AWS, GCP, and Azure) in just 7 minutes.
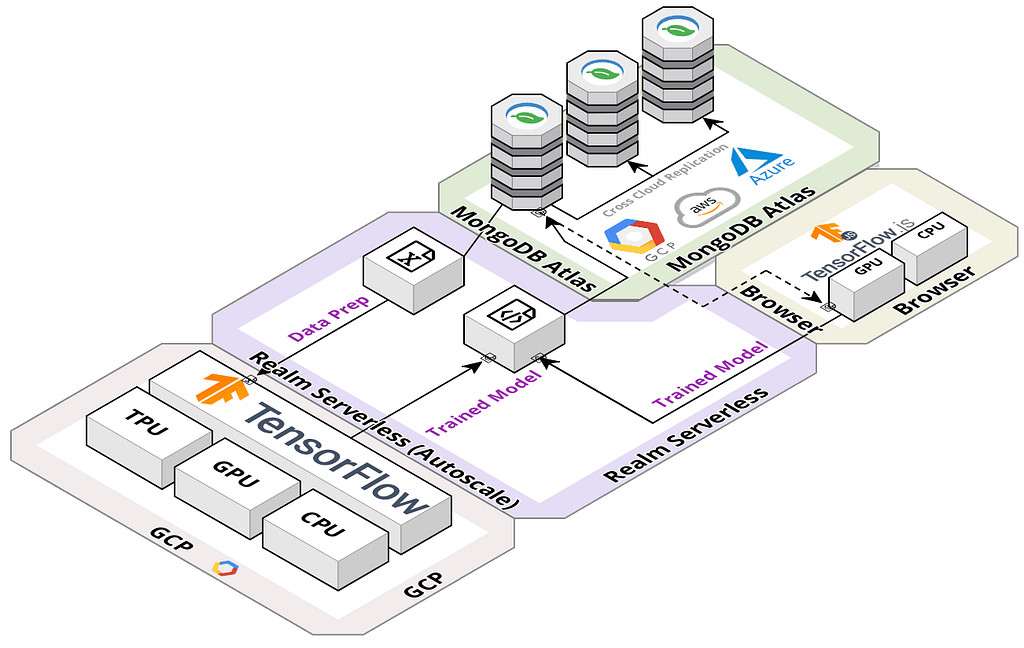
I desired to have a visually appealing demo, so I began my journey by looking into a way to provide machine learning capabilities through a web browser. I found the TensorFlow playground application where I could build my own neural network to solve classification problems utilizing my laptop’s GPU and the web browser. You can play with it as well by clicking the link below.
The playground application allows you to build and train a neural network in your web browser. Following on the heels of the successful playground application, Google released deeplearn.js in August of 2017 to allow developers to used javascript in the browser to do machine learning. In April of 2018, Google took what they had learned from deeplearn.js, and released it into the TensorFlow family by officially releasing TensorFlow.js.
I chose TensorFlow.js to showcase the power of machine learning with MongoDB Atlas and Realm in the Browser for the following reasons:
- Zero Installation: No Drivers / No Installations
- Interactive: It’s Interactive, you can play with the data.
- Sensors: It has access to Sensors, Webcams, and Smart Phone Data with standard APIs to access the sensors
- Distributed: Data can be processed and remain on the client
For these reasons, I selected TensorFlow.js and the browser for a very powerful customer demonstration. Gone are the days where you had to install a complex Hadoop infrastructure with Spark and write complex functions and logic just to do machine learning. Today With MongoDB Atlas, Tensorflow.js, and a browser you can do highly interactive machine learning with zero installation and very little complexity. The barriers to machine learning have been removed.
The result was a rather polished demo with the webpage hosted serverless in MongoDB Realm. I recorded a 7-minute demo to share with the customer. After a follow-up meeting and a hands-on demonstration, the customer signed up and began the process of integrating machine learning into their applications. I have posted the video of the application below:
After being in awe of machine learning for so long I was quite gratified to use it and see how easy it was to get started and be productive with TensorFlow.js and MongoDB. I did not have to install any infrastructure or write any complex machine learning. I was able to write my first program in 88 lines of code and run it in my browser over a weekend. This is the code below…
<html>
<head>
<!-------------------------------------------------------------------------
-- Version Date Author Comments
---------------------------------------------------------------------------
-- 1.0 10/05/2020 Britton LaRoche Initial Version
--
---------------------------------------------------------------------------
-->
https://unpkg.com/realm-web@0.9.0/dist/bundle.iife.js
https://cdn.jsdelivr.net/npm/@tensorflow/tfjs/dist/tf.min.js
<script>
const appId = "YOUR-APP-ID"; // Set Realm app ID here.
const appConfig = {
id: appId,
timeout: 1000,
};
async function run() {
let user;
try {
const app = new Realm.App(appConfig);
const credentials = Realm.Credentials.anonymous(); // create an anonymous credential
user = await app.logIn(credentials);
console.dir(user);
result = await user.functions.fnc_loadCSV("https://raw.githubusercontent.com/brittonlaroche/realm-tensorflow/main/data/fuel_sales_price.csv","InventoryDemo","FuelSales");
console.dir(result);
const mongo = app.services.mongodb("mongodb-atlas");
const db = mongo.db("InventoryDemo");
const coll = db.collection("FuelSales");
items = await coll.find({});
console.log("Items Length: " + items.length);
console.dir(items);
//---------------------------------------------------------
//-- Data prep
//---------------------------------------------------------
var numDocs = items.length;
var xInput =[];
var yOutput = [];
var priceTemp = [];
var totalSales = 0;
for (i=0;i<numDocs;i++){
//priceTemp = [items[i].price, items[i].high_temperature];
//totalSales = items[i].sales_total;
xInput[i] = items[i].price;
yOutput[i] = items[i].sales_quantity;
}
//---------------------------------------------------------
//-- Tensor flow / ML Prediction Below
//---------------------------------------------------------
// Define a model for linear regression.
const model = tf.sequential();
model.add(tf.layers.dense({units: 1, useBias: true, activation: 'linear', inputShape: [1]}));
model.compile({loss: 'meanSquaredError', optimizer: 'sgd'});
// Generate some synthetic data for training.
//const xs = tf.tensor2d([1, 2, 3, 4], [4, 1]);
//const ys = tf.tensor2d([1, 3, 5, 7], [4, 1]);
console.dir(xInput);
console.dir(yOutput);
const xs = tf.tensor2d(xInput, [numDocs, 1]);
const ys = tf.tensor2d(yOutput, [numDocs, 1]);
// Train the model using the data.
model.fit(xs, ys, {epochs: 100}).then(() => {
// Use the model to do inference on a data point the model hasn't seen before:
model.predict(tf.tensor2d([3.25], [1, 1])).print();
// Open the browser devtools to see the output
});
} finally {
if (user) {
user.logOut();
}
}
}
run().catch(console.dir);
</script>
<p>Check the console</p>
Collapse
</head>
<body>
</body>
</html>
The above code ran and made a prediction, and I was amazed at how easy the process had been. Obviously, the model wasn’t trained properly and the prediction was not correct, but it did perform as expected, it just needed more training.
If you are interested in learning more about machine learning with TensorFlow.js watch a video playlist with 3 sections. I highly recommend watching the following 3 videos, about 7 minutes each. It will be the best 21 minutes you can spend to learn all the core concepts:
If you are interested in learning more I suggest you try it yourself. In a couple of hours, you can recreate the entire demo and perform your own fully functional demo with a free tier of Atlas. It costs nothing and you will learn a great deal. Check out the GitHub here: https://github.com/brittonlaroche/realm-tensorflow
I hope this article was helpful and I was able to communicate the wide-open possibilities available to you today with TensorFlow, the Google AI platform, and MongoDB Atlas.
Don’t forget to give us your ? !




4 Reasons Why MongoDB Atlas is great for Machine Learning was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.