
Co-author: Richard Vogg

Acquiring a new customer in the financial services sector can be as much as five to 25 times more expensive than retaining an existing one. Therefore, prevention of costumer churn is of paramount importance for the business. Advances in the area of Machine Learning, availability of large amount of customer data, and more sophisticated methods for predicting churn can help devise data backed strategy to prevent customers from churning.
Imagine that you are a large bank facing a challenge in this area. You are witnessing an increasing amount of customers churn, which has starting hitting your profit margin. You establish a team of analysts to review your current customer development and retention program. The analysts quickly uncover that the current program is a patchwork of mostly reactive strategies applied in various silos within the bank. However, the upside is that the bank has already collected rich data on customer interactions that could possibly help get a deeper understanding of reasons for churn.
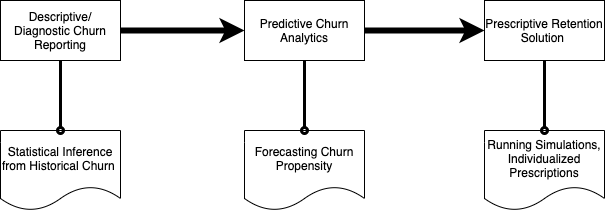
Based on this initial assessment, the team recommends a data driven retention solution which uses machine learning to identify the reasons for churn and possible measures to prevent it. The solution consists of an array of sub-solutions focused towards specific areas of retention. The first level of sub-solutions consists of insights that can be directly derived from the existing customer data, answering for example the following business questions:
- Churn History Analysis: What are characteristics of churning customers? Are there any events that indicate an increased probability for churn, like long periods without contact to the customer, several months of default on a credit product etc.?
- Customer Segmentation: Are there groups of customers that have similar behavior and characteristics? Do any of these groups show higher churn rates?
- Customer Profitability: How much profit is the business generating by different customers? What are characteristics of profitable customers?

First results can be drawn by these analyses. Additional insights are generated by combining them with data points such as the historical monthly profit that a business loses due to churn. Further, the data can be used for training supervised machine learning models which allow predicting future months or help classifying customers for which rich data is not available yet. This is the idea behind the second level of sub-solutions.
- Customer Life Time Value: What is the expected profitability for a given customer in the future?
- Churn Prediction: Which customers are in risk of churn? For which customers a quick intervention can improve retention? The early detection of customers at risk of churn is crucial for improving retention. However, not only is it beneficial to know the churn likelihood but also the expected profit loss that is connected with each customer in case of churn. Constant and fast advances in the area of Machine Learning help to improve these results.
Being able to process large amounts of data allows for more customized results that are focused on the individuality of each customer. This is an important point as every customer has different preferences when it comes to contact with the bank, different reactions when it comes to offers and different needs and goals. Combining previously mentioned analyses and a large amount of customer data provides the third level of sub-solutions which allow individualized prescriptive solutions for at-risk customers. The idea behind this prescriptive retention solution is the simulation of alternative paths combined with optimization techniques along different parameters like how many days passed since the last contact of the client with the bank.
Trending AI Articles:
1. Preparing for the Great Reset and The Future of Work in the New Normal
The first set of descriptive or diagnostic solutions can be implemented relatively quickly as siloed analytics teams within the bank are already exploring them on their own. The second set of solutions which is more predictive in nature could take upto an year to implement. Built atop these, the prescriptive solution utilizes the outcome of previous analyses to suggest improved and individualized retention strategies. As a result the bank can now take different preventive retention measures for each customer.
Comments welcome!
Don’t forget to give us your ? !




Optimizing Retention through Machine Learning was originally published in Becoming Human: Artificial Intelligence Magazine on Medium, where people are continuing the conversation by highlighting and responding to this story.


